
In this Article
To scrape search results at scale — track keyword rankings, build a SERP dataset, monitor competitors, or feed an SEO tool — you need IPs that Google and Bing don’t flag as bots. Search engines personalize results by location, language, and device and throttle automated queries hard, so a SERP scraper either routes through clean proxies or buys a managed SERP API that handles the unblocking for you. This guide covers how SERP scraping actually works in 2026, the proxy-vs-SERP-API decision, and the 8 best options for SERP scraping and rank tracking — compared by price, geo control, and what they return.
I’m Andrii Byzov, an AI-Native Fractional CMO who runs SEO and SERP data pipelines daily. Below: why SERPs block you, how to pick between raw proxies and a SERP API, and the 8 picks — with DataImpulse residential at $1/GB (datacenter $0.50/GB) as the value baseline. For the broader SEO/rank-tracking buyer’s view, see our best proxies for SEO & rank tracking guide; this page goes deeper on the SERP-scraping layer itself.
Key Facts
- SERPs are geo-, language-, and device-personalized. Accurate rank tracking means querying from an IP in the target location with the right
gl/hlparams and device user-agent — otherwise the positions you record aren’t the ones real users see. - Two ways to get SERP data: raw proxies (you send the query and parse the HTML yourself — cheapest) or a managed SERP API (you get parsed JSON, anti-bot handled — pricier per request).
- Datacenter is fine for plain, non-localized SERPs at volume; residential is needed for clean, localized results. Google flags datacenter ranges fastest, so localized rank tracking leans residential.
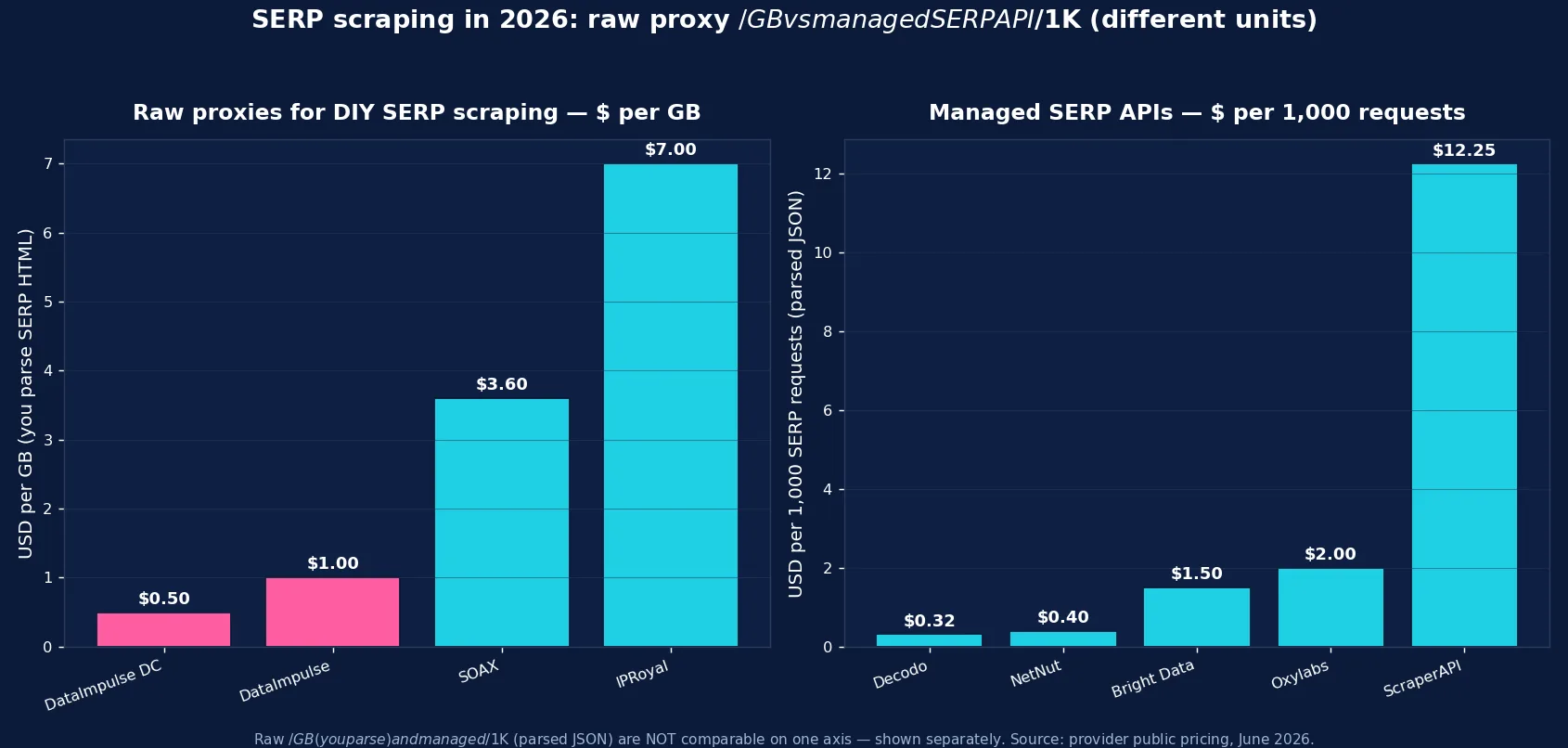
- SERP API pricing is per 1,000 requests and ranges widely — from ~$0.30/1K (Decodo) to ~$12/1K (ScraperAPI’s Google endpoint at 25 credits/request).
- DataImpulse is the value pick for DIY SERP scraping — residential $1/GB, datacenter $0.50/GB, pay-as-you-go, 90M+ IPs, 195 countries, city/ZIP/ASN targeting; a SERP HTML page is a tiny fraction of a GB, so per-1K SERP cost on a $/GB model is very low.
Why scraping SERPs needs proxies
Search engines are among the hardest targets on the web. Google throttles automated queries aggressively — a handful of rapid requests from one IP triggers a CAPTCHA or a soft block, and datacenter IP ranges get flagged fastest of all. Worse for rank tracking: the SERP is personalized. Results differ by country, city, language, device, and search history, so a position you record from a US datacenter IP is not the ranking a user in Berlin on mobile actually sees. To collect accurate, location-true SERP data at scale you need a pool of clean IPs in the right geographies, rotated so no single IP burns out — which is exactly what residential proxies provide, and why “serp proxy” and “rank tracker proxies” are real, high-intent searches.
Proxy vs SERP API: which do you need?
This is the core decision, and it comes down to who does the parsing and unblocking:
- Raw proxies (DIY). You send the search query through the proxy, get back SERP HTML, and parse it yourself (or via your rank tracker). Cheapest per result — you pay for bandwidth, and a SERP page is small — but you own the parser, retries, and CAPTCHA handling. Best if you already run a scraper or rank-tracking engine and want the lowest cost at scale.
- Managed SERP API. You send a keyword + location and get back structured JSON (organic results, ads, People Also Ask, etc.) with anti-bot, rendering, and parsing handled. Costs more per 1,000 requests, but you ship faster and skip parser maintenance. Best for teams that want SERP data as an outcome, not a pipeline to babysit.
Many teams mix both: a SERP API for the volatile, parse-heavy targets (Google with all its SERP features) and raw proxies for cheap, high-volume or simpler checks. The rest of this guide compares both kinds.
Best Proxies & SERP APIs for SERP Scraping at a Glance
| Provider | Type | Best for | Indicative price |
|---|---|---|---|
| DataImpulse | Raw proxies (res + datacenter) | Best value DIY SERP scraping & local rank tracking | $1/GB res, $0.50/GB DC |
| Decodo | SERP API + proxies | Cheapest managed SERP API entry | SERP API from ~$0.30/1K |
| NetNut | SERP API + proxies | High-volume managed SERP | SERP API ~$0.40–1.20/1K |
| Bright Data | SERP API + proxies | Enterprise SERP features & coverage | SERP API ~$1.50/1K; $499/mo tier |
| Oxylabs | SERP API + proxies | Enterprise SLA & parsing accuracy | SERP API from ~$49/mo (~$1.50–2/1K) |
| SOAX | Web Data API + proxies | Mixed residential + mobile SERP | $3.60/GB res; Web Data API for SERP |
| ScraperAPI | SERP API + proxies | SERP as a managed outcome | Google SERP = 25 credits (~$12/1K) |
| IPRoyal | Raw proxies | Budget DIY SERP scraping | Residential from ~$7/GB |
The picks, briefly
DataImpulse is the value baseline for DIY SERP scraping and local rank tracking — residential at $1/GB and datacenter at $0.50/GB, pay-as-you-go with traffic that never expires, 90M+ IPs across 195 countries, plus country/city/ZIP/ASN targeting so you can pin a query to the exact market you’re tracking. Because a SERP HTML page is a tiny fraction of a GB, the effective cost per 1,000 SERP queries on a $/GB model is very low — decisively cheaper than per-request SERP APIs once you run your own parser. Support is 24/7 human; 99.51% published success; G2 4.8.
Decodo (formerly Smartproxy) has the cheapest managed SERP API entry — from roughly $0.30/1K on its entry tiers — plus residential proxies if you want to DIY. NetNut offers a SERP API from about $0.40/1K at entry up to ~$1.08–1.20/1K on production volume commitments, with location, device, and pagination params. Bright Data is the enterprise SERP-features pick — a SERP API at ~$1.50/1K (you pay only for successful requests; parsing and unblocking included) on tiers starting near $499/mo, with the broadest result-type coverage. Oxylabs SERP Scraper API starts around $49/mo (roughly $1.50–2/1K) and drops further at enterprise scale, with strong parsing accuracy and an SLA. SOAX delivers SERP through its Web Data API on top of 155M+ residential and 33M+ mobile IPs (residential around $3.60/GB), good when you need mobile-localized SERPs. ScraperAPI returns Google SERP structured data at 25 credits per request (~$12/1K on the $49/mo plan) — convenient as a managed outcome but the priciest per SERP here. IPRoyal (residential from ~$7/GB) is a budget raw-proxy option for simple DIY SERP checks.
How much does SERP scraping cost?
Two pricing models that aren’t directly comparable. Raw proxies bill per GB of bandwidth — DataImpulse $1/GB residential, $0.50/GB datacenter, SOAX $3.60/GB, IPRoyal ~$7/GB — and since a SERP page is small, the per-1,000-query cost is a fraction of a cent of bandwidth (you supply the parser). Managed SERP APIs bill per 1,000 successful requests with parsing included — Decodo ~$0.30/1K, NetNut ~$0.40–1.20/1K, Bright Data ~$1.50/1K, Oxylabs ~$1.50–2/1K, ScraperAPI ~$12/1K for Google. Rule of thumb: if you scrape SERPs at high volume and already have (or want) your own parser, raw proxies win on cost; if you want parsed JSON with zero anti-bot work, a SERP API is worth the per-request premium.
Datacenter vs residential for SERP scraping
The right IP type depends on how localized and defended your queries are. Datacenter proxies ($0.50/GB) are the cheapest and fastest, and they work for plain, non-localized SERP scraping at volume — broad keyword pulls where you don’t need a specific city’s results and can tolerate occasional CAPTCHAs and retries. Residential proxies ($1/GB) are the choice for accurate, localized rank tracking: real consumer-ISP IPs in the exact target country/city return the SERP a local user actually sees and sustain volume without getting flagged. Mobile proxies ($2/GB) matter when you track mobile-specific SERPs or the toughest targets. The common pattern: datacenter for cheap broad scraping, residential for geo-true rank tracking, mobile for mobile-SERP and the hardest endpoints — and DataImpulse offers all three on one pay-as-you-go account so a pipeline can route each query to the right tier.
Rotating vs sticky for SERP scraping
For SERP scraping you want rotating proxies almost always — a fresh IP per query spreads requests across the pool so no single IP trips Google’s rate limits, which is exactly the profile of high-volume keyword tracking where each query is independent. Sticky sessions (holding one IP for minutes) only matter for multi-step flows — paginating deep into one result set, or a logged-in search context — which is rare in pure rank tracking. Set the right gl (country) and hl (language) parameters and a device user-agent on each request so the rotated IP and the query parameters agree on the same locale.
Common SERP scraping mistakes
- Tracking rankings from the wrong location — using a US IP (or no geo targeting) to record positions for a German or mobile audience gives you rankings nobody actually sees.
- Pointing datacenter IPs at heavy, localized Google queries — fast blocks and CAPTCHA walls; use residential for localized accuracy.
- Querying too fast from too few IPs — burns the pool; rotate widely and pace requests.
- Mismatched
gl/hland IP geo — a German IP with US parameters returns inconsistent SERPs; align them. - Over-paying with a per-request SERP API at scale — once volume is high and you have a parser, raw residential per-GB is far cheaper.
Is it legal to scrape SERP data with proxies?
Scraping publicly available search results is broadly defensible in the US — the 9th Circuit’s hiQ v LinkedIn (2022) held the CFAA doesn’t bar access to public data, and an early-stage district-court ruling in Meta v Bright Data (N.D. Cal. 2024) went in the scraper’s favor on logged-out public data — and using proxies to do it is legal. SERP rank tracking is a long-standing, mainstream SEO practice that every major tool relies on. The caveats are contractual and operational, not about the data being secret: search-engine terms of service prohibit automated querying, so the practical risks are rate-blocking and ToS friction rather than the data itself, which is public and non-personal. Stay in the defensible lane: collect public, read-only SERP data, respect rate limits, don’t bypass logins, and avoid scraping personal data that may appear in results. This is general information, not legal advice — consult counsel for a commercial SERP-data product.
How to start SERP scraping with DataImpulse
Step 1. Create a DataImpulse account and grab your proxy credentials — residential for localized rank tracking, datacenter ($0.50/GB) for cheap broad pulls. The $5 / 5GB intro never expires, so it’s a real test budget.
Step 2. Point your SERP scraper or rank tracker through the proxy with country (and city/ZIP if needed) targeting, set gl/hl and a device user-agent to match, and use rotating IPs so each keyword query gets a fresh address.
Step 3. Pull the SERP HTML through the proxy and parse positions, ads, and SERP features into your tracker or dataset. See the residential proxies and datacenter proxies pages, and the best proxies for SEO & rank tracking guide for the broader workflow.
FAQ
What is a SERP proxy?
A SERP proxy is a proxy IP used to send search-engine queries and collect the results page (SERP) without being blocked. Because Google and Bing throttle automated queries and personalize results by location, a SERP proxy lets you query from a clean IP in the target geography and rotate addresses so no single IP gets flagged — the foundation of rank tracking and SERP datasets.
What’s the best proxy for SERP scraping and rank tracking?
For DIY scraping at the lowest cost, raw residential proxies — DataImpulse at $1/GB ($0.50/GB datacenter) is the value pick, with city/ZIP/ASN targeting for accurate local rankings. If you’d rather get parsed JSON with anti-bot handled, a managed SERP API like Decodo (~$0.30/1K), NetNut, Bright Data, or Oxylabs is the route. Most teams mix both.
Do I need a SERP API or just proxies?
Proxies if you already run a scraper or rank tracker and want the cheapest cost — you parse the HTML yourself. A SERP API if you want structured JSON (organic results, ads, People Also Ask) with rendering and anti-bot handled, and you’ll pay per 1,000 requests for that convenience. High-volume pipelines often use raw proxies; teams wanting a quick outcome use a SERP API.
Can I use datacenter proxies for SERP scraping?
Yes, for plain, non-localized SERP pulls at volume — datacenter is cheapest ($0.50/GB) and fast, though Google flags datacenter ranges soonest, so expect CAPTCHAs and retries. For accurate, location-specific rank tracking use residential IPs in the target market; reserve mobile for mobile-SERP and the hardest endpoints.
How much does SERP scraping cost?
Two models. Raw proxies bill per GB — DataImpulse $1/GB residential, $0.50/GB datacenter — and a SERP page is small, so per-1,000-query bandwidth cost is tiny (you supply the parser). Managed SERP APIs bill per 1,000 requests with parsing included: Decodo ~$0.30/1K, NetNut ~$0.40–1.20/1K, Bright Data ~$1.50/1K, Oxylabs ~$1.50–2/1K, ScraperAPI ~$12/1K for Google.
Is SERP scraping legal?
Scraping public search results is broadly defensible (hiQ v LinkedIn 2022, Meta v Bright Data 2024) and using proxies is legal; rank tracking is standard SEO practice. The caveat is that search-engine terms of service prohibit automated querying, so the risk is rate-blocking and ToS friction, not the public data itself. Respect rate limits, don’t bypass logins, and avoid personal data. Not legal advice — consult counsel for a commercial product.

 State/City/Zip/ASN Targeting
State/City/Zip/ASN Targeting 



