
In this Article
Reddit is among the most-cited AI training sources in 2026 — Semrush and other industry analyses put Reddit at roughly 2-4× the citation frequency of Wikipedia in LLM outputs — and the most expensively-licensed: Google pays Reddit ~$60M/yr (publicly reported, February 2024), OpenAI signed a separate licensing deal in May 2024 (terms not officially disclosed; industry estimates put it around $70M/yr) for licensed access to the same data that’s freely visible on the web but explicitly off-limits to scrapers under Reddit’s user agreement. That gap is why Reddit sued Anthropic (June 4, 2025) for unlicensed Claude training, and filed Reddit v Perplexity in SDNY on October 22, 2025 — naming **Perplexity, SerpApi, Oxylabs UAB, and AWMProxy as co-defendants** in the unlicensed-scraping case (AWMProxy is alleged to have operated a botnet; Oxylabs and SerpApi are accused of facilitating the scraping infrastructure). Reddit’s Data API tiers start at **$12,000 annually for the Standard commercial tier** with $0.24/1,000 requests overage and rate-limit options 100–1,000 RPM; enterprise is custom-quoted and starts much higher. For ML teams, sentiment-analysis vendors, brand-monitoring SaaS, and AI training-data pipelines that can’t afford $12K-$1M/yr licensed access, the practical question is: can you scrape Reddit’s public web layer with residential proxies + Playwright stealth, and what’s the legal exposure if you do? The answer is nuanced — the CFAA coast is clear (post-hiQ), but Reddit’s contract law is enforceable, and the brand-name lawsuits in 2025 show Reddit takes enforcement seriously.
This guide ranks the 8 best proxies for Reddit scraping in 2026, walks through Reddit’s anti-bot stack (Cloudflare + behavioral fingerprinting + OAuth token requirements), explains where licensed API access wins over scraping, covers the legal landscape post-Reddit-v-Anthropic, and reviews the production patterns that survive Reddit’s escalation tiers. Jump to the quick comparison for a thirty-second shortlist.
Key Facts
Reddit scraping is its own proxy market because the legal regime cracked open in 2025, the rate limits are aggressive, and Reddit’s anti-scraping enforcement is real. Five things to know up front:
- Reddit Data API tiers are expensive. Free tier: OAuth-authenticated, 100 RPM, personal/academic/non-commercial use only. Standard commercial pricing is custom-quoted (Reddit doesn’t publish a public rate card) — industry-reported floor is around $12,000/year with $0.24 per 1,000 requests as the published per-request rate. Rate-limit tiers from 100-1,000 RPM, costing proportionally more (200 RPM ~$24K/yr, 500 RPM ~$60K/yr). Enterprise: custom-quoted (Reddit-Google ~$60M/yr, Reddit-OpenAI ~$70M/yr give the price ceiling). The commercial cliff is steep — most ML/SaaS teams that need bulk Reddit data hit this wall and look for alternatives.
- Reddit sued scraping providers in 2025. Reddit v Anthropic (June 4, 2025, San Francisco Superior Court) alleges Anthropic scraped Reddit content to train Claude without a license. Reddit v Perplexity et al. (October 22, 2025, SDNY) named Perplexity, SerpApi, Oxylabs UAB, and AWMProxy as co-defendants in the alleged unlicensed scraping operation — AWMProxy is alleged to have operated a botnet, while Oxylabs and SerpApi are alleged to have provided scraping infrastructure that enabled the operation. This is the first major case where Reddit went after proxy and search-API providers directly, signaling that vendors in production-scale Reddit scraping carry contract-breach exposure of their own.
- Reddit’s anti-bot stack is tier-2 but well-tuned. Cloudflare + behavioral fingerprinting + OAuth-token verification + account-tied risk scoring (post-2023 API changes, even unauthenticated access through old.reddit.com requires careful cadence). Industry community reports through early 2026: open-source anti-detect browsers like Camoufox paired with residential proxies achieve high pass rates (community testing consistently reports near-100% on simple subreddit reads, lower on logged-in flows). Datacenter IPs flag fast; residential and ISP-residential are the default for any production scraping.
- Pushshift archive is restricted to mods. Pushshift was historically the public Reddit archive (17B+ posts going back to 2008), but post-2023 it’s only available to verified Reddit moderators for moderation use cases. The Pushshift archive cannot be the basis of commercial Reddit scraping anymore — production teams must scrape live or license via Reddit Data API.
- Reddit is among the top AI citation sources. Per industry analyses (Semrush 2024-2025 and similar studies), Reddit is cited 2-4× more frequently than Wikipedia in AI model outputs. The Reddit-Google ($60M/yr publicly reported) and Reddit-OpenAI (~$70M/yr industry estimate, terms not officially disclosed) licensing deals reflect this: AI labs view Reddit’s discussion data as foundational training corpus. For brand monitoring, sentiment analysis, market research, and competitive intel, Reddit is the single highest-signal source on the open web — which is exactly why Reddit charges premium pricing for licensed access.
How We Selected These Reddit Proxies
We picked these 8 providers because they have credible residential or ISP-residential coverage that survives Reddit’s anti-bot layer in 2026, public pricing as of May 2026, and documented features that matter for Reddit-specific workflows — long sticky sessions for OAuth-token-bound flows, residential IPs with country diversity for multi-region subreddit work, ISP-residential for account-tied Reddit Pro/Recruiter accounts, or managed Reddit Scraper APIs that shift the anti-bot fight to the proxy vendor. We weighed live PAYG residential price per GB, sticky-session ceiling, Reddit-specific benchmark presence, and post-October-2025 legal posture. Providers without verifiable Reddit success rates were cut. Important context: all eight providers operate in the same legal grey zone as Oxylabs was when Reddit named it as co-defendant in October 2025 — proxy infrastructure for Reddit scraping is a real exposure surface, not just a technical one. Use this list with contract-law-aware counsel.
What Makes a Good Proxy for Reddit Scraping?
A strong Reddit proxy stack solves four problems at once. Residential or ISP-residential authenticity — Reddit’s behavioral fingerprinting layer is tuned to flag datacenter IPs within tens of requests; consumer-ISP residential is the floor for any meaningful Reddit scraping. Sticky sessions of hours-to-days — for OAuth-token-bound flows and account-tied Reddit scraping, IP rotation breaks the session-fingerprint correlation that Reddit’s risk-scoring expects. Country diversity for multi-region subreddit work — r/Brasil, r/india, r/Germany, r/Mexico, r/Russia all have regional sticky posts, mods, and community context that differ by visitor IP geo; multilingual training corpora need authentic regional IPs. TLS-fingerprint-aware client pairing — proxies alone don’t beat Cloudflare; you need to pair with Playwright stealth, curl_cffi, undetected-chromedriver, or Camoufox (the open-source Reddit-bypass darling of 2026). The proxy is half the equation; the client fingerprint is the other half.
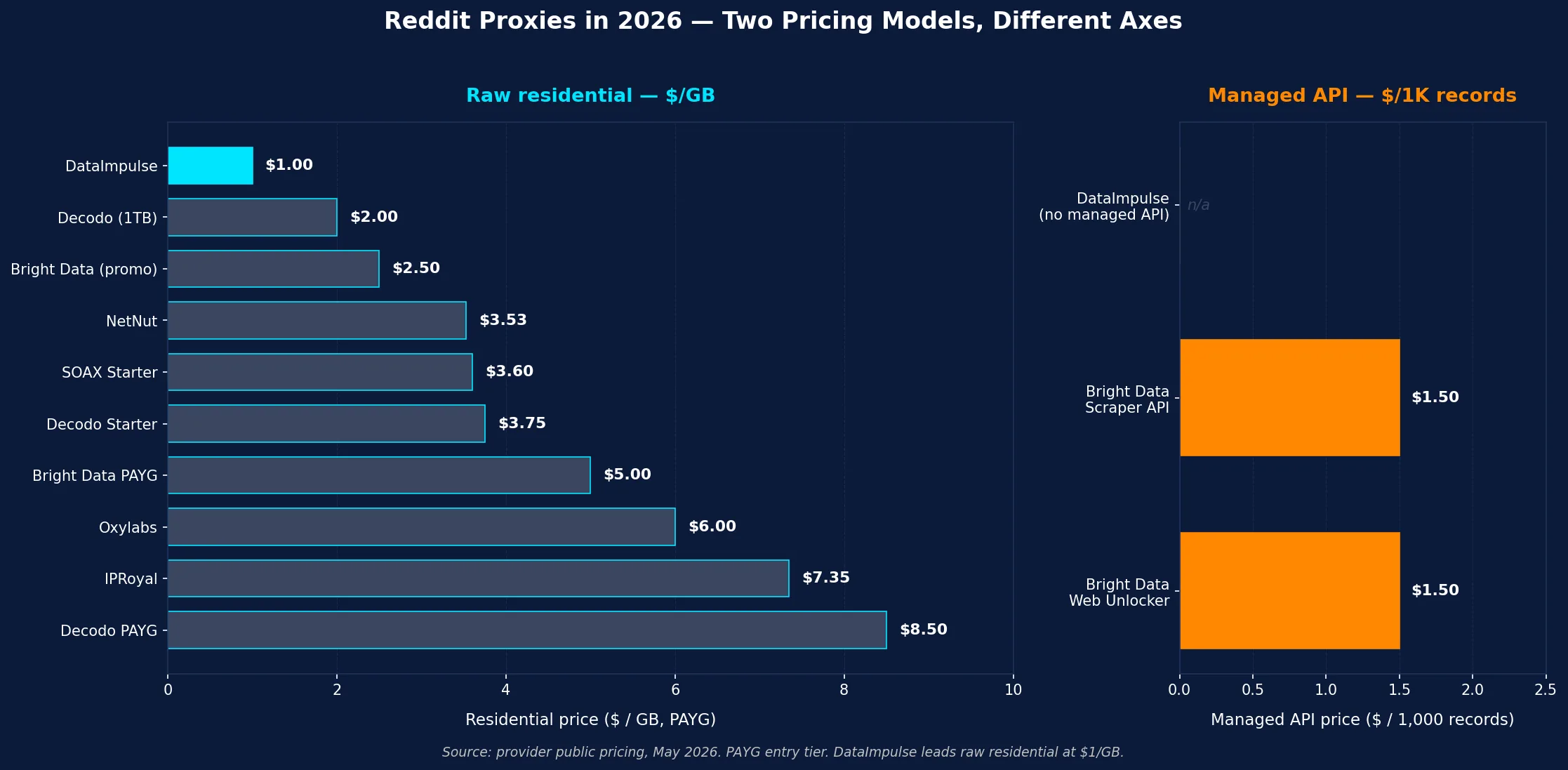
Quick Comparison: Best Proxies for Reddit Scraping at a Glance
| Provider | Best for | Residential price | Sticky | Notable |
|---|---|---|---|---|
| DataImpulse | Best value, in-house Reddit teams | $1/GB PAYG | Rotating + sticky | 90M+ pool, mobile $2/GB for hardest accounts |
| Bright Data | Enterprise + managed Reddit datasets | ~$4/GB PAYG (50% promo); $8/GB regular | Sticky, dedicated | Reddit Scraper API + pre-scraped Reddit datasets |
| Oxylabs | Enterprise (but: Reddit v Oxylabs co-defendant Oct 2025) | from $6/GB | Sticky | Web Scraper API supports Reddit; 99.95% success |
| Decodo | Mid-market, cheap US ISP for Reddit accounts | $3.75/GB starter, $4-$8.50/GB PAYG | Sticky 24h | US ISP from $0.27/IP |
| IPRoyal | Account-tied workflows | from $7.35/GB | Sticky up to 7 days | Longest sticky on list — Reddit-account-survival winner |
| SOAX | Mixed (mobile + ISP for hardest cases) | $3.60/GB Starter | Sticky | 33M+ mobile pool for the hardest Reddit accounts |
| Webshare | Cheap public-Reddit-only | from $3.50/mo res; $2.99/mo DC | Plan-dependent | NOT for account-tied Reddit work |
| NetNut | ISP-residential reliability | from $3.53/GB | Sticky | Consumer-ISP (Comcast, Charter, AT&T) authenticity |
Which Proxy Type Should You Use for Reddit?
Reddit scraping in 2026 splits cleanly into two lanes: public Reddit (subreddit pages, post lists, comment threads via old.reddit.com or the public web layer) and account-tied Reddit (Sales/Recruiter equivalents, signed-in Pro accounts, OAuth-authenticated workflows). Each lane needs different proxy posture.
Residential Proxies — Default for Public Reddit Scraping
Residential proxies are the right default for public Reddit work — subreddit catalog scraping, public post and comment extraction, search-result aggregation, multilingual community scraping (r/Brasil, r/India, r/Russia, r/Mexico, etc.), trend detection, sentiment monitoring, brand-mention tracking. Real Comcast, Charter, AT&T, Verizon, BT, Deutsche Telekom IPs read as ordinary Reddit readers to Cloudflare + behavioral fingerprinting, and a fresh residential pool routinely clears the gauntlet where datacenter ranges flag within tens of requests.
ISP / Static Residential Proxies — Default for Reddit Account-Tied Work
ISP proxies (static residential) are the right choice for any Reddit workflow that needs session continuity or persistent account identity — OAuth-authenticated API consumers (Reddit Data API rate-limit-tier accounts), signed-in Reddit Pro accounts, account-tied automation, multi-day session continuity for Reddit cadence work. ISP IPs sit on consumer-ISP-assigned addresses with the stability of static hosting; Decodo (from $0.27/IP), IPRoyal, NetNut, Bright Data, and Webshare all offer ISP product lines.
Mobile Proxies — Hardest Accounts Only
Mobile proxies route through real carrier networks (Verizon, T-Mobile, AT&T in US; Vodafone, EE in EU) and earn their place for the hardest Reddit accounts — accounts that already hit the next escalation tier on residential, accounts with high karma/age that Reddit’s risk-scoring watches harder, or new account warm-up where mobile-carrier IPs look most native. Mobile is the most expensive per GB ($2-$10), so reserve for the hardest cases.
Datacenter Proxies — AVOID for Reddit
Datacenter proxies are essentially dead for Reddit scraping in 2026. Reddit’s Cloudflare + behavioral fingerprinting layer flags datacenter ranges within tens of requests. Don’t use datacenter for any Reddit surface. Reserve datacenter for adjacent public-data layers (Common Crawl mirrors of Reddit historical content via Wayback Machine, third-party press coverage of Reddit-trending topics).
Rotating vs Sticky for Reddit
The rule for Reddit: rotate for breadth, stick for account/OAuth continuity. Rotating residential handles broad subreddit catalog sweeps, multi-subreddit post-list aggregation, trend monitoring across r/all and r/popular, multilingual community scraping. Sticky sessions (24h minimum, 7-day ideal for the hardest accounts) handle the deeper flows — OAuth-token-tied API consumers, Reddit Data API rate-limit-tier accounts, signed-in Pro/Mod workflows, multi-day cadence-aware content browsing. Most production Reddit stacks are 60% rotating + 40% sticky for the account-tied layer.
Best Proxies for Reddit — Full Reviews
The picks below are ranked on value for Reddit scraping — the balance of residential/ISP authenticity, sticky-session length, country diversity for subreddit work, anti-bot success rate, and price per successful scrape. DataImpulse leads on value; IPRoyal’s 7-day sticky is uniquely strong for account-tied Reddit work; Bright Data is the enterprise managed-Reddit-Scraper-API pick post-Meta-v-Bright-Data legal track record.
1. DataImpulse
DataImpulse is the best-value pick for in-house teams running their own Reddit scrapers — subreddit catalog scraping, comment-thread harvesting, sentiment monitoring across r/wallstreetbets/r/stocks/r/CryptoCurrency for finance teams, brand mention tracking, multilingual community scraping (r/Brasil, r/India, r/Russia, r/Mexico), AI training data assembly from Reddit. Residential starts at $1/GB, pay-as-you-go, with traffic that never expires — a fraction of what licensed Reddit Data API access costs (Standard tier $12K/year minimum) and far below enterprise-managed-API per-record pricing. The pool is 90M+ ethically sourced IPs across 195 countries with credible US/EU coverage — meaningful for both English-language Reddit and the multilingual subreddit communities. Country targeting is included with state/city/ZIP/ASN as a paid add-on (2× the per-GB rate). It supports HTTP, HTTPS, and SOCKS5, rotating and sticky sessions, full API access, and standard scraping stacks (Scrapy, Selenium, Playwright + stealth, Camoufox, undetected-chromedriver). Mobile is available at $2/GB for US/EU carrier networks — the escalation layer to reach when residential gets flagged on the hardest Reddit accounts.
What makes it the default for serious in-house Reddit collection is the legal-audit posture combined with the price-to-pool ratio. Ethically sourced IPs (DI publishes consent SDK documentation) matter more post-Reddit-v-Perplexity-and-Oxylabs (October 2025) — when proxy providers themselves are now named in scraping lawsuits, IP-provenance documentation becomes part of your contract-breach defense. At $1/GB you can sustain continuous Reddit collection without the per-record managed-API charges, and the PAYG model means experimenting with new subreddit data targets doesn’t lock you into a subscription. Support is 24/7 human; published success rate is 99.51%; G2 is 4.8/5.
Quick specs — Types: residential, mobile, datacenter · Pool: 90M+ residential, 195 countries, ethically sourced · Rotation: rotating + sticky · Geo: country (state/city/ZIP/ASN as paid add-on at 2× rate) · Price: $1/GB res, $0.50/GB DC, $2/GB mobile · Published success: 99.51% · Rating: G2 4.8.
Best for: in-house Reddit scraping teams that want low PAYG pricing and audit-defensible IP sourcing.
2. Bright Data
Bright Data is the enterprise pick if you want Reddit data as a managed product. Beyond raw residential at $8/GB pay-as-you-go (currently discounted to ~$4/GB with a 50% promo on the regular PAYG tier, with deeper $2.50/GB on the $1,999/mo high-volume tier) with a 400M+ monthly IP pool and free city/ZIP/ASN targeting, Bright Data ships a dedicated Reddit Scraper API endpoint at $1.50 per 1,000 records on PAYG (about $1.30/1K on the $499/mo plan). The Web Unlocker at $1.50/1K results handles Reddit-protected surfaces generically. Bright Data also publishes pre-scraped Reddit datasets as a separate product (millions of post/comment records, refreshed periodically, sold as bulk data) — for ML teams that want Reddit training data without running the scraping pipeline themselves. ISO 27001, SOC 2 Type II, and audit-ready compliance — and Bright Data won Meta v Bright Data (Jan 23, 2024) on the public-vs-logged-in distinction, giving them the strongest legal track record on this list for public Reddit data scraping.
Quick specs — Types: residential, DC, ISP, mobile + dedicated Reddit Scraper API + Web Unlocker + bulk Reddit datasets · Pool: 400M+ monthly residential · Rotation: rotating, sticky, dedicated · Geo: country/city/ZIP/ASN free · Price: ~$4/GB res PAYG (promo, $8 regular); ~$2.50/GB at $1,999/mo tier; Reddit Scraper API from $1.50/1K records PAYG (~$1.30/1K on $499 plan); subscription from $499/month · Compliance: ISO 27001, SOC 2 Type II.
Best for: enterprise Reddit data teams that want managed Scraper APIs or bulk Reddit datasets with audit-ready compliance.
3. Oxylabs
Oxylabs sits next to Bright Data at the enterprise top with strong Reddit coverage — residential starts around $6/GB on the entry plan with a 175M+ pool across 195 countries, city/state/ZIP/ASN targeting, and a Web Scraper API ($49/mo entry) that supports Reddit as a target with 99.95% published success rate. Important context: Oxylabs was named as co-defendant in Reddit v Perplexity (October 22, 2025, SDNY) alongside Perplexity, SerpApi, and AWMProxy in the unlicensed-scraping case. This is among the first major cases where Reddit targeted proxy and search-API providers directly as co-defendants. The litigation is ongoing as of mid-2026 and Oxylabs has not been found liable. For procurement-grade Reddit work, this is worth weighing — Oxylabs offers strong technical infrastructure and ISO 27001 + SOC 2 compliance, but the legal-risk lens has shifted since October 2025.
Quick specs — Types: residential, DC, ISP, mobile + Web Scraper API · Pool: 175M+ residential, 195 countries · Rotation: flexible, sticky, unlimited concurrency · Geo: country/state/city/ZIP/coordinates/ASN · Price: from $6/GB residential; Web Scraper API from $49/month · Published success: 99.95% · Compliance: ISO 27001, SOC 2 · Active litigation: co-defendant in Reddit v Perplexity (Oct 2025).
Best for: enterprise Reddit programs that want SLA-grade scraping with the caveat that legal-risk posture has shifted since October 2025.
4. Decodo
Decodo (formerly Smartproxy) is the mid-market sweet spot for Reddit account-tied work. Residential proxies start at $3.75/GB on the 3 GB starter plan, with PAYG ranging from $4-$8.50/GB depending on tier/page. The static residential/ISP starts at $0.27/IP — one of the most aggressive ISP rates for the Reddit account-tied workflows where ISP-residential is non-negotiable (OAuth-token accounts, dedicated Reddit Pro seats, multi-day Reddit cadence sessions). Country, city, ZIP, and ASN targeting are included with 115M+ IPs across 195+ locations. The Web Scraping API includes templates for Reddit-style targets, with sticky sessions up to 24 hours.
Quick specs — Types: residential, DC, ISP, mobile + Web Scraping API · Pool: 115M+ residential, 195+ countries · Rotation: per-request, sticky up to 24h · Geo: country/city/ZIP/ASN included · Price: $3.75/GB starter, $4-$8.50/GB PAYG, $2/GB at 1TB+; static residential/ISP from $0.27/IP · Published success: 99.86%.
Best for: mid-market Reddit teams that want cheap ISP for dedicated account-tied scrapers.
5. IPRoyal
IPRoyal earns the top Reddit-specific lane for one reason — 7-day sticky sessions, the longest on this list. Reddit account-tied work survives longer with sticky-session continuity that spans business days; the account-IP fingerprint correlation that Reddit’s risk-scoring tracks rewards consistent IP identity over time. Residential PAYG runs $7.35/GB at entry (cheaper at volume) with a 32M+ pool across 195+ countries with country, region, city, and ISP targeting. There’s a dedicated US ISP product line and a Web Unblocker (CAPTCHA + anti-bot bypass) at per-request pricing. For OAuth-token-bound Reddit accounts, Pushshift-substitute archives requiring multi-day continuity, and any Reddit workflow where session-fingerprint stability over weeks is gating, IPRoyal is the strongest pick.
Quick specs — Types: residential, ISP, mobile, DC + Web Unblocker · Pool: 32M+ residential, 195+ countries · Rotation: rotating, sticky up to 7 days · Geo: country/region/city/ISP · Price: from $7.35/GB residential PAYG.
Best for: Reddit account-tied workflows (OAuth-authenticated, signed-in Pro accounts, Pushshift-substitute archives) that need 7-day sticky continuity.
6. SOAX
SOAX is the pick when mixed proxy types matter for a Reddit program — residential for broad subreddit catalog scraping, mobile for the hardest Reddit accounts, ISP for account-tied OAuth workflows. Residential starts at $3.60/GB on the Starter plan (25 GB included), and the unified credit model means you can spend the same budget on residential, mobile, ISP, datacenter, or the Web Data API. The pool is one of the larger in the mid-tier — 155M+ residential, 33M+ mobile (strong for hardest Reddit accounts where mobile-carrier IPs are the last unblocked lane), 2.6M+ ISP — with country, region, city, ISP, and ASN targeting. Sticky sessions are supported across all proxy types.
Quick specs — Types: residential, mobile, ISP, DC + Web Data API · Pool: 155M+ residential, 33M+ mobile, 2.6M+ ISP · Rotation: per request or interval, sticky supported · Geo: country/region/city/ISP/ASN · Price: $3.60/GB Starter.
Best for: Reddit teams running mixed-type stacks (residential + ISP + mobile) under one subscription.
7. Webshare
Webshare earns its place for Reddit teams running cheap, low-volume public-Reddit-data work — old.reddit.com public-page scraping, public subreddit catalog (when not behind Cloudflare’s strictest config), public-comment aggregation on minor subreddits with weaker defense. Plans start at $2.99/month for the 100-proxy datacenter package and $3.50/month for the entry rotating residential plan with 80M+ residential available on higher tiers, plus static US ISP proxies on subscription plans. Webshare residential is best on public-Reddit work only; for any account-tied or main-Reddit-domain scraping, step up to ISP-focused providers above. The datacenter products do not work on Reddit.
Quick specs — Types: residential, static ISP, datacenter · Pool: 80M+ residential (subscription); datacenter and ISP available · Geo: country, plan-dependent city · Price: from $2.99/month datacenter (100 proxies); rotating residential from $3.50/month.
Best for: cheap, low-volume public-Reddit work. NOT for account-tied scraping or main Reddit.com surface.
8. NetNut
NetNut closes the list with a focus on ISP-residential reliability for Reddit workflows — clean consumer-ISP IPs (Comcast, Charter Spectrum, Verizon FiOS, AT&T, Cox in US; Deutsche Telekom, Vodafone, BT in EU) that hold consistent identity across Reddit session lifecycles. Rotating residential currently starts around $3.53/GB on entry plans, scaling up by volume; country and city-level targeting available on higher tiers. NetNut’s value-prop for Reddit is the consumer-ISP authenticity: IPs read as ordinary Reddit readers, which is exactly what Reddit’s behavioral model expects from typical users. Pair NetNut ISP with sticky sessions and slow human-like cadence for multi-week Reddit account survival.
Quick specs — Types: ISP-residential, residential, mobile · Pool: ISP-grade residential with deep US/EU coverage · Rotation: rotating, sticky · Geo: country (city on higher plans) · Price: from $3.53/GB residential.
Best for: Reddit teams that want consumer-ISP-residential authenticity without paying enterprise prices.
How Much Does Reddit Scraping Cost?
Three economic paths in 2026:
- Licensed Reddit Data API (legally cleanest): Free tier (100 RPM, OAuth, personal/academic only). Standard commercial: $12,000/year starting + $0.24/1K requests over allocation. Rate-limit tiers 100-1,000 RPM cost proportionally more. Enterprise custom-quoted (Google ~$60M/yr, OpenAI ~$70M/yr at scale).
2. Proxy + Playwright stealth + Camoufox (technical path, $0.50-$10/GB residential): DataImpulse residential at $1/GB PAYG covers most production Reddit programs; mobile at $2/GB for the hardest accounts. Practical at-scale cost: $50-$500/mo for typical brand-monitoring / sentiment-analysis programs, $500-$5K/mo for ML training data assembly. Contract-breach exposure is real but most teams accept it.
3. Managed Reddit Scraper APIs (legal-shift-to-vendor): Bright Data’s Reddit Scraper API at $1.50/1K records PAYG (~$1.30 on $499/mo plan), Oxylabs Web Scraper API entry $49/mo, Apify Reddit Scraper Actors with compute-based pricing. Practical at-scale cost: $200-$2K/mo. Bright Data won Meta v Bright Data (Jan 2024) and has the strongest legal track record on the public-vs-logged-in distinction — relevant insurance for Reddit work.
The real cost question for Reddit isn’t “what’s the cheapest path” but “what’s the lowest total cost — including legal-risk reserve — per usable Reddit record.” For most production teams, in-house residential ($1-$2/GB) plus a small legal reserve beats licensed Reddit API at $12K/year minimum until you cross ~5M records/month; above that, managed APIs win on operations time.
Is Reddit Scraping Legal?
Reddit scraping in 2026 sits at the intersection of CFAA, state common law (post-hiQ), Reddit’s user agreement (explicitly enforceable per Reddit’s litigation strategy), and the wave of 2025 lawsuits Reddit filed against Anthropic and Perplexity + Oxylabs. The basics:
- Public-data scraping is CFAA-safe. hiQ v LinkedIn (9th Cir. April 2022) confirmed scraping publicly accessible web data does not violate the Computer Fraud and Abuse Act. Meta v Bright Data (Jan 23, 2024) reinforced this with the public-vs-logged-in distinction. Reddit’s public pages (subreddit indexes, post lists, comment threads accessible without login) fall under hiQ’s CFAA carve-out.
- BUT — Reddit’s user agreement IS enforceable under contract law and state-tort law. Reddit’s Terms of Service explicitly prohibit automated access without a Reddit Data License Agreement (DLA). Following the hiQ playbook (where LinkedIn won contract-breach claims even after losing on CFAA), Reddit sued Anthropic (June 4, 2025) and Perplexity + Oxylabs (October 22, 2025) for breach of Reddit’s user agreement. For commercial Reddit scraping, contract-breach claims are the real exposure surface — not CFAA.
- Reddit’s enforcement against proxy and search-API providers is new. The October 2025 Reddit v Perplexity case (SDNY) named Perplexity, SerpApi, Oxylabs UAB, and AWMProxy as co-defendants. AWMProxy is alleged to have operated a botnet; Oxylabs and SerpApi are alleged to have provided scraping infrastructure. This is among the first major cases where Reddit went after proxy and search-API vendors directly as co-defendants. This signals that infrastructure providers in production-scale Reddit scraping carry contract-breach exposure of their own — not just the AI/SaaS company using the proxy. Choose proxy providers with ethically-sourced IPs and documented compliance posture; the IP-provenance documentation is part of your contract-breach defense.
- Personal data on Reddit triggers GDPR/CCPA/state-privacy law. Usernames, post content authored by identifiable people, and aggregated user profiles are personal data under GDPR (EU members), CCPA/CPRA (California). Strip personal data from corpora where possible; document the strip step.
- The licensing tier exists for a reason. Reddit-Google ($60M/yr) and Reddit-OpenAI ($70M/yr) set the price floor for licensed Reddit data at the high end. The $12K/year Standard tier is the practical license for SaaS/ML teams. Many production Reddit programs run in the grey zone (residential proxies + Playwright stealth, no license, accepting contract-breach risk); the question is whether your organization can absorb a Reddit cease-and-desist or Reddit-v-You lawsuit if you’re high-profile enough to trigger one.
The honest reading: public-Reddit scraping is CFAA-safe, but Reddit’s user-agreement contract-breach exposure is real and well-litigated in 2025. Bigger AI/SaaS companies have been targeted (Anthropic, Perplexity, Oxylabs); smaller teams typically fly under the radar but exposure is non-zero. Get US tech-transactions counsel familiar with the post-October-2025 Reddit-litigation landscape before scaling a production Reddit pipeline. This isn’t legal advice.
How to Start Reddit Scraping with DataImpulse
- Create an account and pick your proxy mix. Residential ($1/GB) for public Reddit subreddit and post-list scraping, multilingual community work, sentiment monitoring; mobile ($2/GB) for the hardest Reddit accounts and account-tied OAuth flows where residential gets flagged; datacenter ($0.50/GB) for adjacent layers (Reddit-trending coverage in third-party news, Wayback Machine mirrors of public Reddit pages — NOT for direct Reddit.com scraping).
- Add funds and build cadence. Pay-as-you-go, no subscription, no expiry. Reddit scraping volume runs in bursts (brand-monitoring monthly cycles, ML training data sprints, trending-topic detection runs). Pair the proxy layer with: Playwright + stealth or Camoufox or undetected-chromedriver client (essential — Reddit’s Cloudflare + behavioral layer flags naive scrapers); slow human-like delays (5-30s between requests, randomized); session-IP continuity for OAuth-authenticated flows.
- Target by subreddit and rotate carefully. Set country US (or specific country for regional subreddit work — UK/CA/AU/DE/BR/IN), pick rotating for broad subreddit-catalog scraping (60-70% of typical workload), pick sticky 24h-7day for OAuth-authenticated workflows. Honor Reddit’s robots.txt where you can, treat user-authored content as personal data, and keep scraping logs for the audit trail you’d want post-incident.
For more on related workflows, see our residential proxies product page, the mobile proxies product page (for hardest Reddit accounts), the best proxies for ML & AI training data collection roundup (Reddit is the #1 source category), and the best proxies for web scraping roundup.
FAQ
Is scraping Reddit legal in 2026?
Public-Reddit data scraping is CFAA-safe under hiQ Labs v LinkedIn (9th Cir. 2022) + Meta v Bright Data (Jan 2024). BUT Reddit’s user agreement explicitly prohibits scraping, and Reddit has aggressively enforced contract-breach claims — Reddit sued Anthropic (June 4, 2025) and Perplexity + Oxylabs (October 22, 2025) for unlicensed scraping. Contract-breach + state-tort claims are the real exposure surface. Personal user data triggers GDPR/CCPA. Get tech-transactions counsel before scaling commercial Reddit pipelines. This isn’t legal advice.
How much does the Reddit Data API cost in 2026?
Free tier: OAuth-authenticated, 100 RPM, personal/academic only. Standard commercial: $12,000/year minimum, with $0.24 per 1,000 requests over allocation. Rate-limit tiers (100-1,000 RPM) cost proportionally more — 200 RPM ~$24K, 500 RPM ~$60K. Enterprise custom-quoted (Reddit-Google ~$60M/yr, Reddit-OpenAI ~$70M/yr set the high-end price ceiling). For most SaaS/ML teams, the $12K cliff is the practical entry point.
What are the best proxies for Reddit scraping without burning accounts?
ISP / static residential is the default for account-tied Reddit (OAuth, signed-in workflows) — Decodo from $0.27/IP, IPRoyal (7-day sticky), NetNut, Bright Data ISP, Webshare ISP. Residential rotating for public-Reddit broad scraping — DataImpulse at $1/GB is the budget pick. Mobile (DataImpulse $2/GB, SOAX 33M+ pool) for the hardest accounts. Don’t use datacenter for Reddit. Always pair with Playwright + stealth, Camoufox, or undetected-chromedriver — proxies alone don’t beat Reddit’s Cloudflare + behavioral fingerprinting.
Can I use Pushshift Reddit archive in 2026?
No, not for commercial use. Pushshift is restricted to verified Reddit moderators for moderation use cases post-2023 changes; the public Pushshift archive (17B+ historical posts going back to 2008) is no longer available to general developers or commercial teams. Production Reddit scraping must scrape live or license via Reddit Data API.
How do I scrape Reddit without getting account-banned?
(1) Use residential or ISP-residential proxies — datacenter ranges flag fast. (2) Pair with Playwright + stealth, Camoufox (open-source Reddit-favorite in 2026), or undetected-chromedriver to defeat Cloudflare’s TLS-fingerprint + JS-challenge layer. (3) Slow human-like cadence — 5-30s between requests, randomized, business-hours-of-the-IP’s-time-zone-only. (4) For OAuth/account work, sticky 24h-7day sessions (IPRoyal’s 7-day is gold-standard for multi-day Reddit cadence). (5) One IP per Reddit account — never share IPs across accounts. (6) Warm up new accounts manually for 1-2 weeks before automation. (7) Honor Reddit’s robots.txt where you can.
Reddit Data API vs scraping — which is more cost-effective?
Depends on volume. For 1-5M records/month: in-house residential proxies + Playwright stealth wins on raw cost ($1/GB + engineering time vs $12K/yr+ Reddit Data API), with the asterisk of contract-breach exposure. Above 5M records/month: Reddit Data API or Bright Data’s pre-scraped Reddit datasets win on operations time + legal cleanliness. For ML training data assembly at scale: Bright Data’s bulk Reddit dataset (sold as periodically-refreshed JSON) is often the best legal+cost combination.
Mobile proxies for Reddit — when?
Three cases: (1) account survival escalation when ISP-residential gets flagged on Reddit accounts hitting the next risk-scoring tier; (2) Reddit mobile app validation where mobile-context surfaces different feed/notification content than desktop; (3) new account warm-up where mobile-carrier IPs look most native during the first 30 days. SOAX (33M+ mobile pool), IPRoyal, DataImpulse, and Bright Data offer Verizon/T-Mobile/AT&T-routed mobile proxies. Reserve mobile for the hardest cases — they cost more per GB.
What about Reddit-Google and Reddit-OpenAI licensing deals?
Reddit signed AI training licensing deals with Google (~$60M/yr starting February 2024) and OpenAI (~$70M/yr, estimated). These set the high-end price ceiling for licensed Reddit data and signal Reddit’s view of its dataset’s commercial value. Reddit is now reportedly negotiating for variable / output-volume-based pricing rather than flat annual rates. For your ML / SaaS team, these deals don’t change anything practical — they’re the ceiling, not your tier. Your options remain: $12K/year Standard tier, or grey-zone scraping with contract-breach acceptance.
Should I worry about Reddit-v-Perplexity (and co-defendants) October 2025?
Yes, if you’re an Oxylabs/SerpApi/AWMProxy customer scraping Reddit at scale OR if you’re a proxy or search-API provider in production Reddit scraping. Reddit v Perplexity et al. (SDNY, October 22, 2025) named Perplexity, SerpApi, Oxylabs UAB, and AWMProxy as co-defendants. AWMProxy is alleged to have operated a botnet; Oxylabs and SerpApi are alleged to have provided scraping infrastructure. This is the first major case where Reddit targeted proxy and search-API providers directly as co-defendants, and outcomes will shape vendor-liability landscape for years. Outcomes will shape the proxy-provider-liability landscape for years. For most ML/SaaS teams using residential proxies for Reddit, the lesson is: choose ethically-sourced providers with documented compliance posture (ISO 27001, SOC 2, consent SDK documentation) so IP-provenance is part of your contract-breach defense. DataImpulse, Bright Data, Oxylabs, and NetNut all publish provenance documentation; smaller/budget providers often don’t.
Ready to run Reddit scraping with the proxy layer that survives Reddit’s Cloudflare + behavioral defense without burning accounts? Start with DataImpulse — residential from $1/GB, datacenter from $0.50/GB, mobile from $2/GB, pay-as-you-go with ethically-sourced 90M+ IPs across 195 countries, country targeting included (state/city/ZIP/ASN as paid add-on), traffic that never expires, and 24/7 human support.

 State/City/Zip/ASN Targeting
State/City/Zip/ASN Targeting 



