
In this Article
The economics of LLM training shifted in 2025-2026: Reddit signed AI licensing deals with Google ($60M/yr) and OpenAI ($70M/yr); Stack Overflow + Cloudflare launched pay-per-crawl in February 2026; a coalition of 1,500+ publishers backs the Really Simple Licensing (RSL) protocol; Reddit sued Anthropic and Perplexity for unlicensed scraping. At the same time, two federal judges — in Bartz v Anthropic (June 23, 2025) and Kadrey v Meta (June 25, 2025) — independently ruled that training on public data is “highly transformative” and protected under fair use. The result: ML teams in 2026 are aggressively collecting public web data at unprecedented scale — Common Crawl alone now spans 2B+ pages and hundreds of terabytes — but they’re doing it through residential proxy infrastructure, not naked datacenter IPs, because the publisher pushback is real and rate limits across the AI-relevant sources have hardened. Whether you’re supplementing Common Crawl with vertical corpora, building multilingual RAG indexes, assembling image-text pairs for diffusion training, or constructing synthetic-data pipelines that query competitors, the right proxy stack is what makes the collection pipeline scale without burning IPs.
This guide ranks the 8 best proxies for AI and ML training data collection in 2026, sorts out residential vs datacenter vs mobile vs ISP for ML pipelines, covers the legal landscape post-Bartz/Kadrey, and walks through full reviews. Jump to the quick comparison for a thirty-second shortlist; deeper coverage follows.
Key Facts
ML/AI training data collection is its own proxy market because the legal regime crystallized in 2025-2026, publisher gatekeeping is intensifying, and dataset volumes have grown two orders of magnitude in three years. Five things to know up front:
- Public-web training is fair use; ToS-and-bot-protection is the real gate. Bartz v Anthropic (June 23, 2025, Judge Alsup) ruled the training use itself “exceedingly transformative” and fair — though Anthropic’s separate downloading of ~7M pirated books for its permanent library was NOT fair use. Kadrey v Meta (June 25, 2025, Judge Chhabria) ruled in Meta’s favor on the developed record but explicitly cautioned that it does NOT stand as broad authority for AI training legality — “these plaintiffs made the wrong arguments.” Individual site ToS and bot protection (Cloudflare, Akamai, PerimeterX) still control practical access. The legal coast is clearer; the technical coast is harder.
- The publishing layer is monetizing. Reddit signed AI licensing deals with Google (~$60M/yr) and OpenAI (~$70M/yr), and is now the most-cited source in AI models — 3× more frequently than Wikipedia. Reddit sued Anthropic (June 2025) and Perplexity (October 2025) for unlicensed scraping. Stack Overflow + Cloudflare launched pay-per-crawl (Feb 2026). RSL (Really Simple Licensing, Sep 2025) gives 1,500+ publishers machine-readable license terms.
- Common Crawl is bedrock; derivative datasets dominate. Common Crawl ships monthly web archives spanning ~2B pages and hundreds of TB. C4 (750 GB, Google), RefinedWeb (600B tokens, Falcon), and RedPajama-V2 (100T tokens, 84 monthly CC snapshots 2014-2023) all derive from it. ML teams supplement CC with vertical/multilingual scrapes — that supplementation is where proxies enter.
- NYT v OpenAI raised the discovery bar. In January 2026, the SDNY court compelled OpenAI to produce all 20M ChatGPT logs (not a hand-picked subset) to NYT plaintiffs. Production-grade ML pipelines should now assume eventual discovery: keep scraping logs, robots.txt-respect records, and license documentation. Proxy provider compliance posture (ISO 27001, SOC 2, ethically-sourced IPs) matters for the audit trail.
- Datacenter IPs flag fast on AI-relevant sources. Reddit, Stack Overflow, news sites (NYT, WSJ, Atlantic), GitHub Codespaces, and major aggregators all run tier-1 anti-bot stacks. Residential and ISP-residential are the default for production AI training data collection. Rate limits cluster around 1-10 RPS per IP on protected sources — your proxy pool size sets your collection throughput.
How We Selected These ML Training Data Proxies
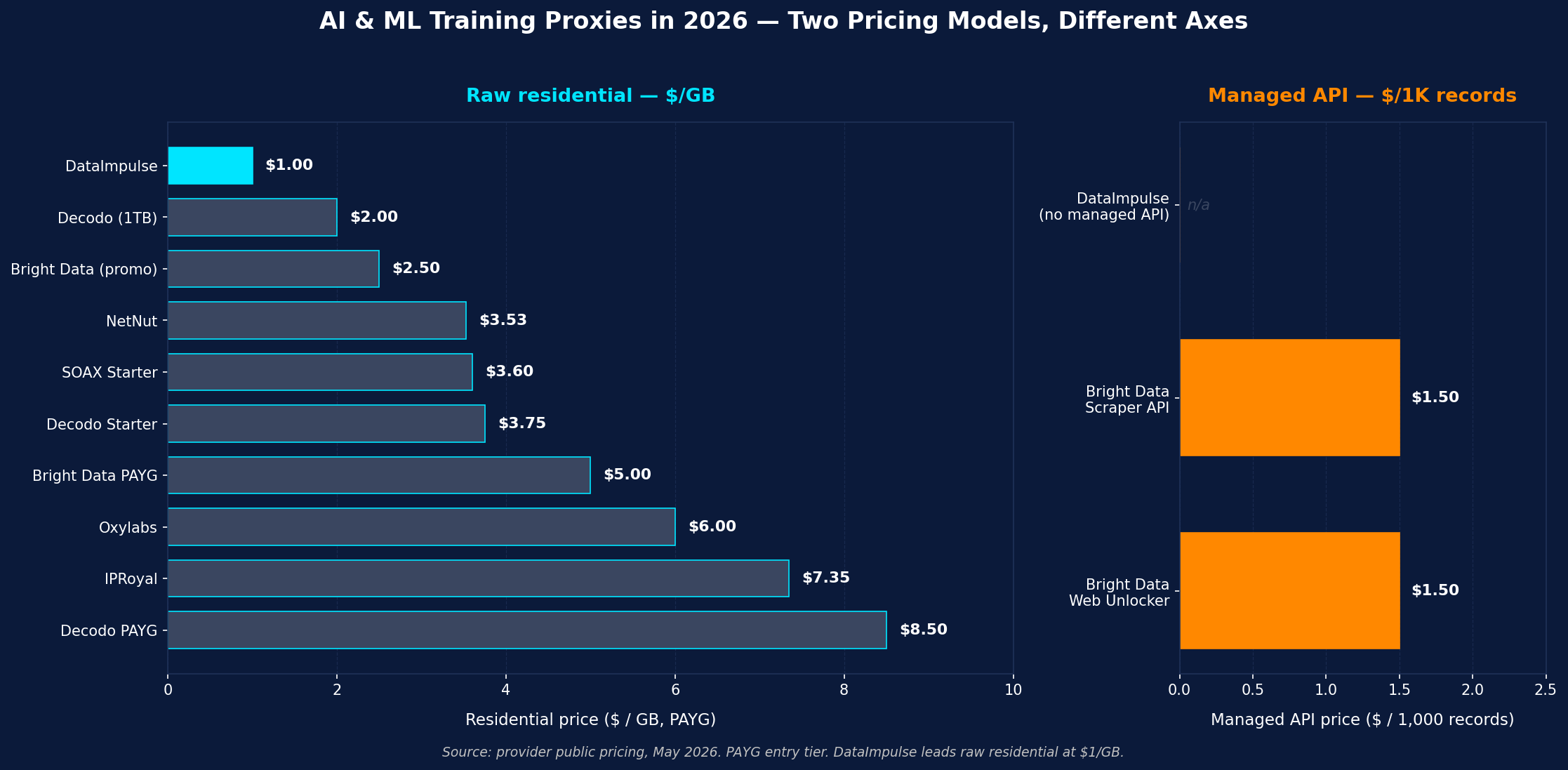
We picked these 8 providers because they have credible large-scale residential IP coverage (ML pipelines burn through pools fast), public pricing as of May 2026, and one or more documented features that matter for AI training collection — multi-region geo for multilingual corpora, sticky sessions long enough for paginated archive crawls, ISP-residential for source-licensee accounts (Reddit Pushshift, GitHub, Stack Exchange API), per-record managed APIs that handle anti-bot generically, or ethically-sourced pools that document IP provenance for the legal-audit trail. We weighed live PAYG residential price per GB, transparency of pricing, freshness of marketing claims, and ranking on independent ML/AI scraping benchmarks. Providers without verifiable global coverage, with stale pricing, or with no public success-rate disclosure were cut.
What Makes a Good Proxy for ML Training Data?
A strong ML-training proxy stack solves four problems at once. Pool depth at country granularity — ML pipelines burn through 10–500GB/month of residential IPs per scraper; pools under 30M IPs exhaust fast and degrade quality. Multi-region coverage (US/EU/Asia/LatAm) is gating for multilingual training corpora and culturally-diverse datasets. Ethically-sourced documentation — post-Reddit-suing-Anthropic and Stack Overflow’s pay-per-crawl, ML teams need IP-provenance documentation for the legal-audit trail. ISO 27001 / SOC 2 compliance is increasingly procurement-required. PAYG with no expiry — ML data collection is spiky: dataset-version-bump cycles, eval-data refresh, vertical-corpus assembly. Subscription lock-in burns budget on idle months. Per-record managed scraper APIs — for teams that don’t want to build and maintain custom parsers against Cloudflare/Akamai, the per-record managed APIs (Bright Data, Oxylabs) shift the bot-protection problem to the proxy vendor. Pick raw proxies for in-house parser teams; pick managed APIs for product/research teams.
Quick Comparison: Best Proxies for ML & AI Training Data at a Glance
| Provider | Best for | Residential price | Pool | Geo | Notable |
|---|---|---|---|---|---|
| DataImpulse | Best value, in-house ML pipelines | $1/GB PAYG | 90M+ residential, 195+ countries | Country free; state/city/ZIP/ASN 2× rate | Ethically sourced; traffic never expires |
| Bright Data | Managed Scraper APIs for AI | ~$2.50/GB (50% promo); $5/GB regular | 400M+ residential | Country/city/ZIP/ASN free | Dedicated Reddit / Stack Overflow / news Scraper APIs |
| Oxylabs | SLA-grade enterprise ML programs | from $6/GB | 175M+ residential | Country/state/city/ZIP/ASN/coords | Web Scraper API; 99.95% success |
| Decodo | Mid-market, multilingual corpora | $3.75/GB starter, $8.50/GB PAYG | 115M+ residential | Country/city/ZIP/ASN included | 195+ locations for multilingual sweeps |
| IPRoyal | Long-running training pipelines | from $7.35/GB | 32M+ residential | Country/region/city/ISP | Sticky up to 7 days |
| SOAX | Mixed proxy types | $3.60/GB Starter | 155M+ res, 33M+ mobile, 2.6M+ ISP | Country/region/city/ISP/ASN | Unified credit; mobile coverage for app-based AI |
| Webshare | Cheap Common Crawl supplementation | from $3.50/mo res; $2.99/mo DC | 80M+ residential (sub) | Country, plan-dependent city | Budget pick for low-defense AI sources |
| NetNut | ISP-residential for clean training data | from $3.53/GB | ISP-grade residential | Country (city on higher plans) | Consumer-ISP IPs (less noisy than DC) |
Which Proxy Type Should You Use for ML Training Data Collection?
ML training data collection behaves differently from one-off scraping work because the volumes are higher (10× to 1000× typical price-tracking jobs), the freshness requirements are looser (data ingested once per training run), and the legal-audit trail matters more (IP provenance for fair-use documentation). The proxy type decides your success rate and your audit posture.
Residential Proxies
Residential proxies are the right default for nearly all serious ML training data collection — Reddit, Stack Overflow, GitHub Codespaces, news aggregators (NYT, WSJ, FT, Atlantic, Politico), Wikipedia mirrors and language editions, academic publishers (Cambridge, Springer, JSTOR public-domain), Medium and Substack newsletters, blog ecosystems, vertical content (legal databases like CourtListener, medical pre-print servers like medRxiv, financial filings like SEC EDGAR public layer), forum and discussion sites, and the long tail of low-traffic specialist sites. Real consumer-ISP IPs read as ordinary readers to the bot defense, and a fresh global residential pool routinely clears Cloudflare’s bot-management layer where datacenter ranges flag in hundreds of requests.
ISP / Static Residential Proxies
ISP proxies (static residential) are the right choice for ML workflows that need session continuity or persistent identity — signed-in Reddit / Pushshift API consumers, Stack Exchange API quota accounts, GitHub authenticated crawls, paid publisher accounts (Bloomberg Terminal feeds, FT subscriptions), and long-running paginated archive crawls of news archives or forum histories. ISP IPs sit on ISP-assigned consumer addresses with the stability of static hosting: residential trust with the predictability of a fixed address. Decodo, IPRoyal, Bright Data, and NetNut all offer ISP product lines.
Mobile Proxies
Mobile proxies route through real carrier networks (Verizon, T-Mobile, AT&T, Vivo, Vodafone, Jio, etc.) and earn their place in ML training data collection for three cases: (1) mobile-first sources (Instagram, TikTok where they’re legally accessible, mobile-app forums like Discord public channels) where mobile IPs are native; (2) app-API endpoints that gate harder on non-mobile IPs (Snapchat public, some mobile-version site APIs); (3) the hardest anti-bot sources (Reddit’s mobile defense, Twitter/X) where rotating mobile IPs are the last unblocked lane. Mobile is the most expensive option per GB, so reserve for jobs where mobile context genuinely matters.
Datacenter Proxies
Datacenter proxies have a narrow but real role in ML training data collection: bulk crawling of low-defense public sources — Common Crawl raw access (it’s a public CDN), public government datasets (data.gov, EU Open Data Portal, data.gov.in), open academic repositories (arXiv, PubMed Central), GitHub public repos via the v3 API, open Wikipedia dumps, Project Gutenberg, and Hugging Face dataset mirrors. Don’t lean on datacenter for Reddit, Stack Overflow, news sites, or any source with serious anti-bot — these flag datacenter ranges within hundreds of requests. Reserve datacenter for the low-defense layer of an ML stack, and switch to residential or ISP as soon as a target starts challenging you.
Rotating vs Sticky for ML Training Data
The rule for ML data collection: rotate aggressively for breadth, stick only for paginated context. Rotating residential handles broad Common Crawl supplementation, Reddit subreddit-level pulls, Stack Overflow tag-level pulls, news-site full-archive sweeps, and forum-history-by-thread crawls. Sticky sessions handle the deeper flows — paginated news archives where you need to follow “next page” links across 50+ pages with the same fingerprint, Stack Exchange threaded discussions, multi-page Reddit thread expansions, and any flow where the server-side state needs IP continuity. Most production ML stacks default 90% rotating + 10% sticky for paginated edge-cases.
Best Proxies for ML & AI Training Data — Full Reviews
The picks below are ranked on value for ML training data collection — the balance of pool depth, geo coverage, anti-bot success rate, ethically-sourced documentation, sticky-session length, and price per successful record. DataImpulse leads on value; the rest each win a specific lane.
1. DataImpulse
DataImpulse is the best-value pick for in-house ML teams running their own training-data scrapers — Reddit supplementation, Stack Overflow corpus assembly, news-archive harvesting, blog/Medium/Substack crawling, multilingual Wikipedia mirroring across 195+ locales, GitHub-adjacent code-doc sites, and vertical corpus assembly (legal, medical, financial). Residential starts at $1/GB, pay-as-you-go, with traffic that never expires — a fraction of what enterprise AI-data scrapers charge, which matters when ML data collection runs in 100GB-to-multi-TB spikes around dataset-version-bump cycles. The pool is 90M+ ethically sourced IPs across 195 countries — meaningful for multilingual training corpora where regional IP authenticity decides whether the data reads as Brazilian-Portuguese or English-translated-pt. Country targeting is included with state/city/ZIP/ASN as a paid add-on (2× the per-GB rate), useful for regional-news training datasets and culturally-specific corpora. It supports HTTP, HTTPS, and SOCKS5, rotating and sticky sessions, full API access, and standard scraping stacks (Scrapy, Selenium, Playwright). Mobile is available at $2/GB for the hardest anti-bot AI sources; datacenter at $0.50/GB for public-data layers (Common Crawl mirrors, open government data, arXiv, public APIs).
What makes it the default for serious ML data collection is the price-to-pool-depth ratio combined with ethical sourcing documentation. At $1/GB you can run continuous multilingual web supplementation for under $1K/TB, and the PAYG model means experimenting with new training-data sources doesn’t lock you into a subscription. The ethically-sourced 90M pool gives you the IP-provenance documentation post-Bartz/Kadrey legal-audit trails increasingly want. Support is 24/7 human; published success rate is 99.51%; G2 is 4.8/5. There’s no dedicated AI-data endpoint here — DataImpulse sells the proxy infrastructure cleanly and lets your ML team build the scraper layer on top, paired with a TLS-fingerprint-aware client (curl_cffi, undetected-chromedriver, Playwright + stealth) for tier-1 anti-bot AI sources.
Quick specs — Types: residential, mobile, datacenter · Pool: 90M+ residential, 195 countries, ethically sourced · Rotation: rotating + sticky · Geo: country (state/city/ZIP/ASN as paid add-on at 2× rate) · Price: $1/GB res, $0.50/GB DC, $2/GB mobile · Published success: 99.51% · Rating: G2 4.8.
Best for: in-house ML/AI teams that want low pay-as-you-go pricing and audit-defensible IP sourcing without enterprise commitments.
2. Bright Data
Bright Data is the enterprise pick if you want ML training data as a managed product. Beyond raw residential at $5/GB pay-as-you-go (currently discounted to ~$2.50/GB with a 50% promo) with a 400M+ monthly IP pool and free city/ZIP/ASN targeting, Bright Data ships dedicated Scraper APIs for Reddit, Stack Overflow, major news sites, social platforms, and search-engine SERPs at $1.50 per 1,000 records on PAYG (about $1.30/1K on the $499 plan). The Web Unlocker at $1.50/1K results handles arbitrary AI-relevant sources generically — point it at Cloudflare-protected blogs, Akamai-fronted news archives, or PerimeterX-defended forums and it returns rendered HTML. ISO 27001, SOC 2 Type II, documented privacy-law compliance (GDPR/CCPA/LGPD-aligned), and audit-ready documentation clear most enterprise procurement and most ML legal-risk reviews. It’s the right call when you’d rather hit a managed Reddit or NYT endpoint than maintain a parser against publisher-side rate-limit and DOM churn — at enterprise pricing with procurement-style buying.
Quick specs — Types: residential, DC, ISP, mobile + dedicated Reddit/Stack-Overflow/news/social Scraper APIs + Web Unlocker · Pool: 400M+ monthly residential · Rotation: rotating, sticky, dedicated · Geo: country/city/ZIP/ASN free · Price: ~$2.50/GB res (promo); $5/GB regular; Scraper APIs from $1.50/1K records PAYG (~$1.30/1K on $499 plan); subscription from $499/month · Compliance: ISO 27001, SOC 2 Type II.
Best for: enterprise ML/AI data teams that want managed Scraper APIs for Reddit/SO/news with audit-ready compliance and SLA controls.
3. Oxylabs
Oxylabs sits next to Bright Data at the enterprise top with deep ML-training coverage. Residential starts around $6/GB on the entry plan with a 175M+ pool across 195 countries and strong geo coverage with city, state, ZIP, ASN, and geographical coordinate targeting (essential for region-specific training corpora). The Web Scraper API ($49/month entry) handles JavaScript rendering, anti-bot bypass, and structured data extraction across AI-relevant sources including Reddit, news sites, and SERPs. Sessions are flexible with unlimited concurrent connections (matters for ML pipelines that fan out to 1000+ concurrent scrapers during dataset-collection sprints), and Oxylabs publishes a 99.95% residential success rate. Pick Oxylabs when reliability, SLA-grade support, ISO 27001 / SOC 2 compliance, and procurement-grade documentation matter more than entry price — particularly for enterprise ML programs that need procurement docs for legal-risk reviews on training-data provenance.
Quick specs — Types: residential, DC, ISP, mobile + Web Scraper API · Pool: 175M+ residential, 195 countries · Rotation: flexible, sticky, unlimited concurrency · Geo: country/state/city/ZIP/coordinates/ASN · Price: from $6/GB residential; Web Scraper API from $49/month · Published success: 99.95% · Compliance: ISO 27001, SOC 2.
Best for: enterprise ML programs that want SLA-grade managed scraping with ISO 27001 / SOC 2 compliance and concurrent-fanout support.
4. Decodo
Decodo (formerly Smartproxy) is the mid-market sweet spot for ML training data work — especially multilingual corpora. Residential proxies start at $3.75/GB on the 3 GB starter plan with PAYG at $8.50/GB on the public pricing page, dropping to about $2/GB at the 1,000 GB tier. Country, city, ZIP, and ASN targeting are included with 115M+ IPs across 195+ locations — meaningful for ML teams building multilingual datasets that need authentic regional IPs (Wikipedia language editions, regional news archives, country-specific forums). The static residential/ISP starts at $0.27/IP — one of the most aggressive ISP rates for static-residential workflows like Reddit Pushshift-style accounts, Stack Exchange API quota accounts, and Common Crawl supplementation runs that span weeks. The Web Scraping API includes templates for major content sources, with sticky sessions up to 24 hours.
Quick specs — Types: residential, DC, ISP, mobile + Web Scraping API · Pool: 115M+ residential, 195+ countries · Rotation: per-request, sticky up to 24h · Geo: country/city/ZIP/ASN included · Price: $3.75/GB starter, $8.50/GB PAYG, $2/GB at 1TB+; static residential/ISP from $0.27/IP · Published success: 99.86%.
Best for: mid-market ML teams building multilingual training corpora or running long static-residential ML accounts.
5. IPRoyal
IPRoyal earns its spot for long-running ML training pipelines — multi-day Common Crawl supplementation sweeps, multi-page paginated news-archive crawls, persistent Reddit account-tied scrapes, long-running forum-history harvests where session continuity over days matters. Residential PAYG runs $7.35/GB at entry (cheaper at volume) with a 32M+ pool across 195+ countries with country, region, city, and ISP targeting. Its real differentiator is sticky sessions up to 7 days, the longest on this list — uniquely useful for multi-day ML data-collection sprints where rotating sessions break paginated server-state, Reddit/SO API-key-tied accounts where session continuity is gating, and long-running training-data assembly pipelines. There’s also an ISP product line and Web Unblocker (CAPTCHA + anti-bot bypass) at per-request pricing.
Quick specs — Types: residential, ISP, mobile, DC + Web Unblocker · Pool: 32M+ residential, 195+ countries · Rotation: rotating, sticky up to 7 days · Geo: country/region/city/ISP · Price: from $7.35/GB residential PAYG.
Best for: multi-day ML data-collection pipelines that need sticky-session continuity across paginated archives.
6. SOAX
SOAX is the pick when mixed proxy types matter for an ML pipeline. Residential starts at $3.60/GB on the Starter plan (25 GB included), and the unified credit model means you can spend the same budget on residential, mobile, ISP, datacenter, or the Web Data API. The pool is one of the larger in the mid-tier — 155M+ residential, 33M+ mobile, 2.6M+ ISP — with country, region, city, ISP, and ASN targeting. Sticky sessions are supported across all proxy types. Convenient if your ML pipeline mixes residential for broad news/forum scrapes, mobile for the hardest sources (Reddit mobile, TikTok-style platforms), and ISP for account-tied API consumers (Reddit, Stack Exchange) under one subscription with shared credit.
Quick specs — Types: residential, mobile, ISP, DC + Web Data API · Pool: 155M+ residential, 33M+ mobile, 2.6M+ ISP · Rotation: per request or interval, sticky supported · Geo: country/region/city/ISP/ASN · Price: $3.60/GB Starter.
Best for: ML teams running mixed-type collection (residential + mobile + ISP) across one subscription.
7. Webshare
Webshare earns its place for ML teams running cheap large-volume crawling on low-defense AI sources — Common Crawl mirror access (it’s a public CDN), public open-data repositories (data.gov, EU Open Data Portal, arXiv, PubMed Central, GitHub public API, HuggingFace dataset mirrors), public-domain text archives (Project Gutenberg, Internet Archive), and low-traffic specialist sites without serious anti-bot. Plans start at $2.99/month for the 100-proxy datacenter package and $3.50/month for the entry rotating residential plan with 80M+ residential available on higher tiers, plus static ISP proxies on subscription plans. Webshare residential is best on lower-defense ML data sources; for tier-1 anti-bot (Reddit, NYT, Stack Overflow), step up to the providers above.
Quick specs — Types: residential, static ISP, datacenter · Pool: 80M+ residential (subscription); datacenter and ISP available · Geo: country, plan-dependent city · Price: from $2.99/month datacenter (100 proxies); rotating residential from $3.50/month.
Best for: ML teams running cheap large-volume crawling on public open-data and low-defense AI sources.
8. NetNut
NetNut closes the list with a focus on ISP-residential reliability for ML training data — clean consumer-ISP IPs that look less synthetic in the audit trail than aggressive rotating-residential pools. The product line emphasizes ISP-grade residential IPs (Comcast, Charter, Vodafone, BT, Deutsche Telekom, and other consumer-ISP-assigned addresses) with rotating and sticky options. Rotating residential currently starts around $3.53/GB on entry plans, scaling up by volume; country and city-level targeting available on higher tiers. NetNut is the pick when you specifically want consumer-ISP-residential network depth for the audit-defensibility lens — the IPs read as ordinary home internet users in any subsequent legal or audit scrutiny of the training-data sources.
Quick specs — Types: ISP-residential, residential, mobile · Pool: ISP-grade residential with deep major-ISP coverage · Rotation: rotating, sticky · Geo: country (city on higher plans) · Price: from $3.53/GB residential.
Best for: ML teams that want consumer-ISP-residential IPs for the audit-defensibility of their training-data collection pipeline.
How Much Do ML Training Data Proxies Cost?
Listed pricing in 2026 falls into three bands. Budget/value at $1–$3.75/GB — DataImpulse, SOAX Starter, Decodo entry, Webshare residential subscription — covers most in-house ML training data collection. Mid/premium at $3.50–$7.35/GB — Bright Data, Oxylabs, IPRoyal, NetNut — adds enterprise tooling, SLA-grade reliability, and audit-ready compliance posture. API-priced and ISP-priced — Bright Data’s Scraper APIs $1.50/1K records PAYG (~$1.30/1K on $499 plan), Oxylabs Web Scraper API from $49/mo, Decodo Web Scraping API from $19/mo, Decodo US ISP at $0.27/IP — sell structured outcomes per record, per plan, or per IP instead of per GB.
The real cost question for ML training data isn’t “what’s the lowest $/GB” but “what’s the lowest cost per successful, audit-defensible training record”. A managed scraper API at $1.30–$1.50/1K records can beat $1/GB residential when your in-house scraper hits Cloudflare or Akamai blocks on 30–50% of requests; conversely, $1/GB residential with a TLS-fingerprint-aware client and sticky sessions for paginated archives routinely beats per-record APIs at multi-TB scale once your in-house parser is mature. For ML budgets running 100GB-1TB/week, raw residential wins on $/record; for smaller research/eval-data needs, managed APIs win on engineering time.
Is It Legal to Use Proxies for ML & AI Training Data Collection?
ML training data law sits at the intersection of US copyright (fair-use post-Bartz/Kadrey), the CFAA (hiQ v LinkedIn), publisher contracts (Reddit/SO licensing), state privacy law (CCPA/CPRA + EU GDPR), and the patchwork of national AI/data laws (DPDP in India, LGPD in Brazil). The basics:
- Training on public web data is fair use (US) — with carve-outs. Bartz v Anthropic (June 23, 2025, Judge Alsup) ruled training itself “exceedingly transformative” and fair use under 17 USC §107 — but downloading ~7M pirated books to build Anthropic’s permanent library was NOT fair use, a separate-and-significant carve-out. Kadrey v Meta (June 25, 2025, Judge Chhabria) ruled for Meta on the record but explicitly cautioned the ruling does not stand as broad AI-training-is-fair authority. The pending Authors Guild v OpenAI and consolidated In re: OpenAI Copyright Infringement Litigation cases will refine the boundary. Public + transformative + non-substitutionary = fair use, with provenance hygiene is the working framework.
- Public-data scraping is CFAA-safe. The 9th Circuit’s hiQ Labs v LinkedIn (2022) ruling established that scraping publicly accessible web data does not violate the Computer Fraud and Abuse Act. Meta v Bright Data (2024) reinforced this with a public-vs-logged-in distinction: public is fine; logged-in account scraping triggers contract-breach exposure.
- Publisher contracts override the fair-use defense for licensed sources. Reddit, Stack Overflow, NYT, WSJ, and the 1,500+ RSL-protocol signatories distribute their data under explicit licensing terms. Scraping these sources for training without a license triggers contract-breach claims (Reddit v Anthropic 2025, Reddit v Perplexity 2025). The fair-use defense doesn’t excuse contract-breach.
- Discovery is the new exposure surface. NYT v OpenAI (January 2026 SDNY ruling): OpenAI was compelled to produce all 20M ChatGPT logs, not a hand-picked subset. Production ML pipelines should assume eventual discovery — keep scraping logs, robots.txt-respect records, license documentation, and proxy-vendor IP-provenance attestations.
- Cross-border privacy law applies to personal data. GDPR (EU), CCPA/CPRA (California), LGPD (Brazil), DPDP Act 2023 (India, phased through 2027) all govern training datasets that contain personal data of residents in those jurisdictions. Scraping personal data without a legal basis is enforceable independent of the fair-use defense. Strip personal data from training corpora when possible, document the strip step for audit.
The honest reading: large-scale ML training on public web data is legally defensible in 2026 under Bartz/Kadrey + hiQ, but the contract layer (Reddit, SO, RSL signatories) and the personal-data layer (GDPR/CCPA/LGPD/DPDP) are real exposure. Public/non-licensed/non-personal data is the lowest-risk lane; licensed-source scraping and personal-data scraping are the highest. Get US copyright + tech-transactions counsel before scaling a production ML training pipeline. This isn’t legal advice.
How to Start ML Training Data Collection with DataImpulse
- Create an account and pick your proxy mix. Residential ($1/GB) for Reddit, Stack Overflow, news archives, forum histories, blog/Substack/Medium scrapes, multilingual Wikipedia mirrors, and vertical corpora (legal/medical/financial); datacenter ($0.50/GB) for enrichment layer (Common Crawl mirrors, arXiv, PubMed, GitHub public API, data.gov, EU Open Data Portal, public-domain archives); mobile ($2/GB) for the hardest anti-bot AI sources where rotating mobile IPs are the last unblocked lane.
- Add funds. Pay-as-you-go, no subscription, no expiry — handy because ML data collection runs in 100GB-to-multi-TB spikes around dataset-version-bump cycles, eval-data refresh, and vertical-corpus assembly sprints, then idles for weeks.
- Plan for the audit trail. Set country targeting matching your corpus regional balance (US/EU/Asia/LatAm for multilingual training; specific countries for regional corpora), choose rotating for breadth + sticky for paginated archives, point your scraper at the proxy endpoint and run. Log every scrape with timestamp, target URL, proxy session ID, and robots.txt-respect outcome — this is your post-Bartz/Kadrey audit defense layer.
For more on related workflows, see our residential proxies product page, the datacenter proxies product page (for Common Crawl and open-data layer), the best proxies for web scraping roundup, and the best proxies for SEO & rank tracking roundup.
FAQ
Is it legal to use proxies for AI training data collection?
For public web data, yes — Bartz v Anthropic (June 23, 2025) and Kadrey v Meta (June 25, 2025) both ruled that training AI on public web data is “highly transformative” and protected by fair use under 17 USC §107. The 9th Circuit’s hiQ v LinkedIn (2022) ruling protects the underlying scraping under CFAA. But publisher contracts (Reddit, Stack Overflow, RSL-protocol signatories) override fair use for licensed sources — Reddit sued Anthropic (June 2025) and Perplexity (October 2025) for unlicensed scraping. Personal data triggers GDPR/CCPA/LGPD/DPDP regardless. Get US copyright + tech-transactions counsel before production. This isn’t legal advice.
What proxies do production LLM training pipelines actually use?
Production ML teams typically run a tiered stack: datacenter proxies ($0.50/GB) for public-data layer (Common Crawl, arXiv, GitHub public API, open repositories); residential proxies ($1–$3.75/GB) for the bulk of web scraping (Reddit, Stack Overflow, news, forums, blogs); mobile proxies ($2–$10/GB) reserved for the hardest anti-bot sources (Reddit mobile, social platforms); and managed Scraper APIs ($1.30–$1.50/1K records) when in-house parsing time is more expensive than per-record cost. DataImpulse, Bright Data, and Oxylabs all show up in production ML stacks.
How does Reddit’s lawsuit against Anthropic affect ML training collection?
Reddit sued Anthropic in June 2025 for unlicensed scraping of Reddit content to train Claude, and sued Perplexity in October 2025 on similar grounds. The Reddit-Google and Reddit-OpenAI licensing deals ($60M/yr and $70M/yr respectively) set the price floor for licensed Reddit data. Practical implication: if your ML pipeline scrapes Reddit at scale, either license it (Reddit Data API) or accept contract-breach exposure. Public-only-CC-supplementation pipelines that include incidental Reddit content via Common Crawl carry materially lower risk.
What about scraping Stack Overflow and Stack Exchange?
Stack Overflow + Cloudflare launched pay-per-crawl in February 2026 — bots are charged at the gateway. The Stack Exchange API has rate limits and ToS prohibiting bulk redistribution. For ML training data, the legal path is: use the public Stack Exchange API quota (with auth), respect the per-IP rate-limits, or license bulk access from Stack Overflow’s enterprise team. Bypass via residential proxies is technically possible but increases contract-breach exposure.
Do I need country diversity in my proxy pool for multilingual training?
Yes for multilingual training corpora. ML teams building genuinely multilingual datasets need authentic IPs from the language regions — Wikipedia-de scraped via US IPs returns English-redirect or English-formatted content sometimes; Reddit subreddit pulls from r/Brasil show different sticky posts based on viewer IP geo; regional news archives geo-fence by visitor country. DataImpulse, Decodo, Oxylabs, and Bright Data all have 195+ country coverage. SOAX and IPRoyal have strong country breadth on entry plans.
How do I make my training data collection audit-defensible?
Five practices: (1) Use ethically-sourced proxy pools (DataImpulse, Bright Data, Oxylabs all publish IP-provenance docs); (2) Log every scrape with timestamp, URL, proxy session ID, response code, and robots.txt-respect outcome; (3) Respect robots.txt where it exists; (4) Strip personal data from training corpora and document the strip step; (5) For licensed sources (Reddit, SO, NYT), maintain license documentation or skip them and rely on Common Crawl’s snapshot. Post-NYT-v-OpenAI January 2026 ruling, assume eventual discovery — the audit trail is no longer optional.
Common Crawl is free — why pay for proxies at all?
Common Crawl covers ~2B pages monthly but lags 1–3 months and skews to high-traffic English-language sites. ML teams use proxies for: (1) supplementation with fresher data (recent news, recent Reddit threads, recent papers); (2) multilingual coverage beyond CC’s English bias; (3) vertical corpora (legal, medical, financial, scientific) that CC under-samples; (4) specific source completeness (e.g., complete Reddit archive vs CC’s sample); (5) personal-data-stripped pipelines where you need real-time scraping to apply your own privacy filters. CC is the bedrock; proxies are the augmentation layer.
Mobile proxies for ML — when do they matter?
Three cases: (1) mobile-first sources (Instagram, TikTok public-domain, mobile app forums) where mobile IPs are native; (2) app-API endpoints that gate harder on non-mobile IPs (some mobile-version site APIs, push-notification feeds); (3) the hardest anti-bot sources where Cloudflare/Akamai/PerimeterX block residential too — mobile carrier IPs are the last unblocked lane. SOAX, IPRoyal, DataImpulse, and Bright Data all offer mobile proxies. Reserve mobile for jobs where mobile context genuinely matters — they cost more per GB and your ML pipeline rarely needs the full mobile premium.
Static residential / ISP proxies for ML — when?
Use ISP/static-residential for ML workflows that need session continuity across days — Reddit Pushshift-style accounts that hold paginated archive context, Stack Exchange API quota accounts, paid publisher accounts (Bloomberg, FT), long-running multi-day forum history harvests where rotation breaks server-side pagination state. Decodo (from $0.27/IP), IPRoyal, NetNut, Bright Data, and Webshare all sell ISP product lines. For one-off ML data sprints, rotating residential is cheaper; for persistent identity, ISP is the only option.
Ready to run audit-defensible ML and AI training data collection at scale? Start with DataImpulse — residential from $1/GB, datacenter from $0.50/GB, mobile from $2/GB, pay-as-you-go with ethically-sourced 90M+ IPs across 195 countries, country targeting included (state/city/ZIP/ASN as paid add-on), and traffic that never expires.

 State/City/Zip/ASN Targeting
State/City/Zip/ASN Targeting 



