
In this Article
AI web scraping crossed a tipping point in 2026 — the market split between purpose-built LLM-ready APIs (Firecrawl, Olostep, Crawl4AI) and the previous-generation general-purpose scrapers retrofitted with AI features (Apify, Octoparse, Browse AI, ScrapingBee, ScraperAPI, ZenRows). For data teams building RAG pipelines, agent web access, fine-tuning datasets, or competitive intelligence corpora, the question is no longer “should we use a scraping tool” but “which tool’s data shape, anti-bot posture, and price model fits our LLM pipeline?” Common Crawl + Firecrawl + Apify Actors are among the largest sources of public web data flowing into AI training and RAG systems today; Bright Data won Meta v Bright Data (Jan 2024) establishing public-data-scraping precedent that the whole industry leans on; Reddit sued Anthropic (June 2025) and Perplexity (October 2025) for unlicensed scraping, signaling that publisher contracts are the real legal exposure — not the CFAA, not the scraping tool.
This guide reviews 10 of the most-used AI web scrapers in 2026, breaks down the LLM-pipeline alignment, pricing models, and anti-bot capabilities, walks through where each tool wins, and explains where proxy infrastructure (the layer underneath every scraper) decides whether your collection program scales or stalls. Jump to the quick comparison for a thirty-second shortlist.
Key Facts
The AI web scraping market in 2026 has unique dynamics worth knowing before picking a tool. Five things to know up front:
- LLM-ready output > raw HTML. Modern AI scrapers (Firecrawl, Crawl4AI, Olostep, Spider.cloud) convert web pages to clean markdown or structured JSON ready for embedding, RAG ingestion, or model fine-tuning. Firecrawl claims its markdown uses ~67% fewer tokens than raw HTML — directly relevant if you’re paying per-token to OpenAI/Anthropic. Generic scrapers (Apify, ScrapingBee, ScraperAPI) return HTML/JSON and require post-processing.
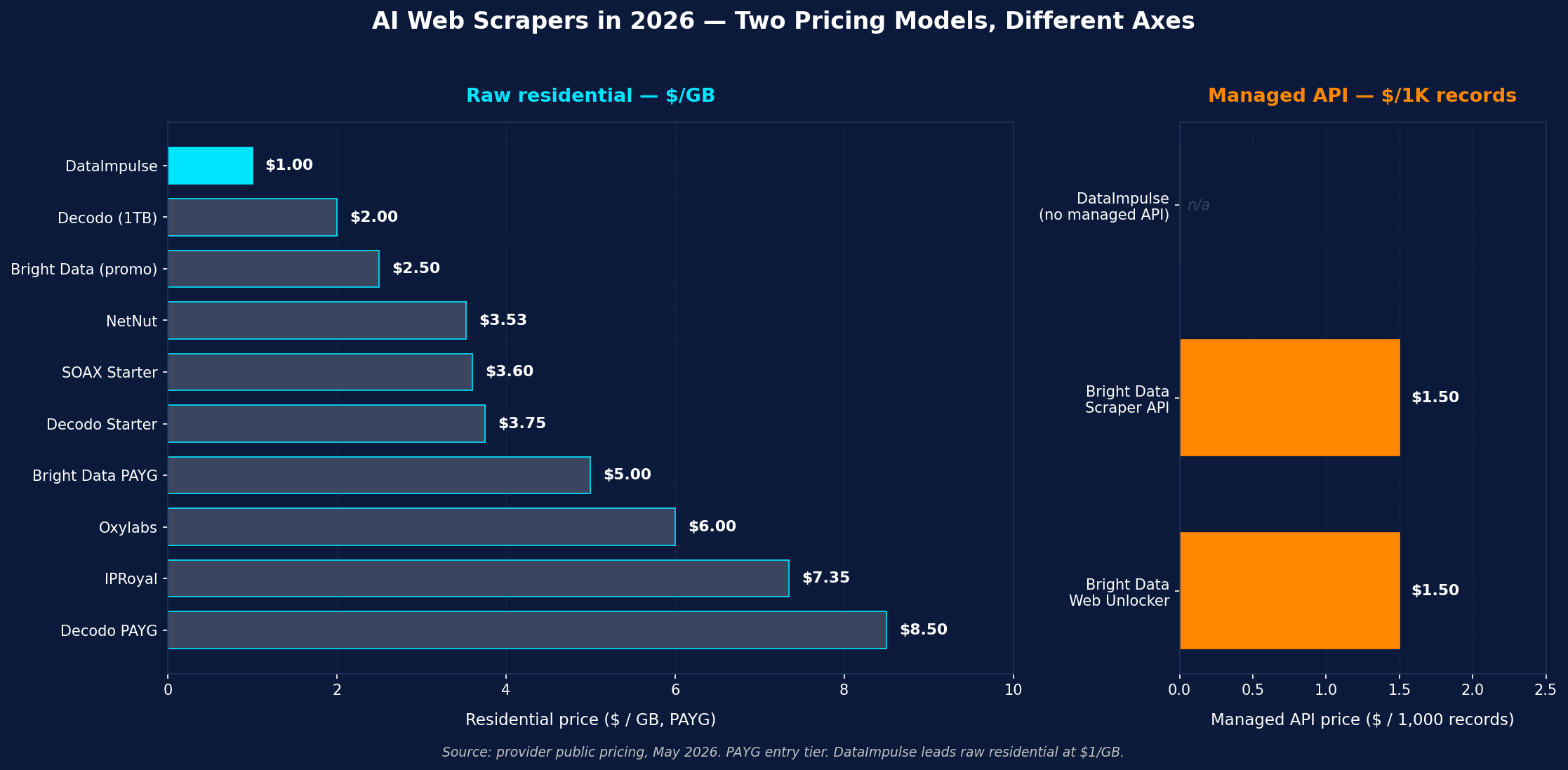
- Pricing models split into three camps. Flat-rate per page/credit (Firecrawl ~$0.0008/scrape at scale, Olostep credit-based), compute-based (Apify ~$0.20-$0.30/compute unit + Actor rental + proxy passthrough), and per-request with multipliers (ScrapingBee, ScraperAPI, ZenRows, Decodo Scraping API — JS rendering and premium proxies can multiply per-request cost 5×-75×). Compute-based is the hardest to forecast; flat-rate is the easiest.
- Anti-bot is the real gate. Per Scrapeway 2024-2025 benchmarks: Bright Data ~98% average success rate (100% on Indeed, Zillow, Capterra, Google). ZenRows + Decodo + Bright Data + Zyte include anti-bot bypass by default; Firecrawl, Apify, ScrapingBee offer it as an add-on or higher tier. For hard targets (Cloudflare/Akamai/PerimeterX-protected sites), the bypass capability matters more than feature breadth.
- Open-source matters more in 2026. Crawl4AI (open-source, AI-native, LangChain/LlamaIndex integrations) and Scrapy + Playwright stealth stacks gained share against managed APIs as ML teams pulled scraping in-house for IP-provenance audit reasons. The trade-off is the proxy layer — open-source scrapers need raw proxy infrastructure underneath.
- Public scraping is legal, contracts are not — and Reddit changed everything. Bartz v Anthropic (Jun 23, 2025) + Kadrey v Meta (Jun 25, 2025) confirmed training on public web data is fair use. Meta v Bright Data (Jan 23, 2024) confirmed scraping public-logged-out is CFAA-safe + ToS-safe. But Reddit v Anthropic (Jun 2025), Reddit v Perplexity + Oxylabs (Oct 2025), Stack Overflow + Cloudflare pay-per-crawl (Feb 2026), and the RSL protocol (Sep 2025, 1,500+ publishers) made publisher contracts the new exposure layer. The legal coast is clearer; the contract coast is harder.
How We Selected These AI Web Scrapers
We picked these 10 tools because they have credible production-scale deployment in 2026, public pricing transparency, documented AI/LLM use cases (markdown output, JSON-LD extraction, structured-data endpoints, LangChain/LlamaIndex integration, agent-MCP support), and a real lane on the AI-pipeline value chain — from open-source self-hosted (Crawl4AI) to managed enterprise APIs (Bright Data Web Scraper, Oxylabs). Tools without published pricing, with stale 2024-era marketing claims, or with no AI-pipeline integration story were cut. We test scrapers regularly on representative AI-workflow targets (Reddit, Stack Overflow, news, Wikipedia, GitHub, e-commerce catalogs) to validate the LLM-pipeline claims.
What Makes a Good AI Web Scraper?
A strong AI web scraper for 2026 solves four problems at once. LLM-ready output structure — markdown or structured JSON is dramatically cheaper to ingest into vector DBs and LLM context windows than raw HTML; tools that don’t ship LLM-friendly output add a cleaning step that costs engineering time and per-token spend. Anti-bot bypass without separate proxy purchase — for the hardest targets (Cloudflare/Akamai/PerimeterX-protected), the scraper either bypasses or you bring proxies on the side; the bundled approach saves operations time, the bring-your-own approach saves money at volume. Predictable pricing aligned to LLM cost models — flat-rate per page beats compute-based for budget control, especially when your downstream LLM cost is also per-token; compounding multipliers (JS rendering + premium proxy + retry-on-fail) make compute-based pricing opaque. Integration with the rest of the LLM stack — native connectors to LangChain, LlamaIndex, AI coding agents via MCP, structured-output schemas (Pydantic, Zod) — these matter more in 2026 than they did in 2024.
Quick Comparison: Best AI Web Scrapers at a Glance
| Tool | Best for | Pricing | LLM-output | Anti-bot |
|---|---|---|---|---|
| Firecrawl | RAG / LLM-ready markdown | $16/mo (5K credits); $0.0008/scrape at scale | Markdown + JSON (native) | Add-on / higher tier |
| Apify | Marketplace breadth (10K+ actors) | Compute-based + Actor rent + proxy | HTML/JSON (post-process) | Per-actor varies |
| Octoparse | Visual point-and-click, no-code | $69/mo Standard (annual) | HTML/CSV (post-process) | Built-in (template-based) |
| Browse AI | No-code prompt-driven | $19/mo entry | JSON | Auto-adapts |
| ScrapingBee | Developer-friendly managed API | $49/mo Freelance | HTML/JSON | Add-on / higher tier |
| ScraperAPI | Hard targets (Amazon, Google) | $49/mo Hobby (100K credits) | HTML/JSON, structured endpoints | Bundled |
| ZenRows | Cloudflare/DataDome/PerimeterX bypass | Per-request + multipliers | HTML/JSON | Bundled (specialty) |
| Crawl4AI | Open-source LLM-friendly | Free (self-host) | Markdown + JSON (native) | Bring your own |
| Bright Data Web Scraper | Enterprise, hardest targets | $1.50/1K records PAYG (~$1.30 on $499/mo) | JSON, structured endpoints | Bundled (best-in-class) |
| Olostep / Spider.cloud | LLM-ready + open-source-friendly | Credit-based, transparent | Markdown + JSON | Bundled |
The AI Scraper Lanes in 2026
AI web scraping in 2026 split into five lanes; pick by your team’s lane, not by feature count.
Lane 1 — LLM-Ready APIs (purpose-built for AI)
The newest and fastest-growing lane: scrapers that exist specifically to feed LLMs. Firecrawl is the lane leader — markdown output, MCP-server support, LangChain + LlamaIndex native integrations, claimed 67% token reduction vs raw HTML. Olostep, Spider.cloud, and fastCRW all play in this lane with similar AI-first product design. Crawl4AI is the open-source play with the same value proposition. Pick this lane if your output is feeding directly into a RAG vector DB or an agent’s context window.
Lane 2 — Marketplace + Actor Ecosystem
Apify dominates this lane with 10,000+ pre-built scrapers (“Actors”) for specific targets (Amazon, LinkedIn, TikTok, Instagram, Twitter/X, Reddit, etc.). The compute-based pricing is harder to forecast but the marketplace breadth means most common targets already have a maintained scraper. Pick Apify if you need scrapers for many different sites and don’t want to build each one.
Lane 3 — No-Code / Visual Builders
Octoparse (visual point-and-click desktop app, $89/mo Standard, template-driven for popular sites), Browse AI (prompt-driven AI selection, $19/mo entry, auto-adapts when sites change), Bardeen (AI automation with web extractor, freemium). Pick this lane if your team doesn’t include engineers comfortable with Playwright/Scrapy.
Lane 4 — Developer Managed APIs (general-purpose)
ScrapingBee ($49/mo Freelance), ScraperAPI ($49/mo Hobby, 100K credits; specialty structured-data endpoints for Amazon/Google/Walmart), ZenRows (specialty in Cloudflare/DataDome/PerimeterX bypass), Decodo Web Scraping API ($19/mo). General-purpose, per-request priced, with multipliers for JS rendering and premium proxies. Pick this lane for hard targets with moderate volume.
Lane 5 — Enterprise Managed Scrapers
Bright Data Web Scraper API (Reddit/Stack Overflow/news/social/LinkedIn/Amazon endpoints; $1.50/1K records PAYG, ~$1.30/1K on $499/mo plan; best-in-class success rate ~98%). Oxylabs Web Scraper API ($49/mo entry, SLA-grade, ISO 27001 + SOC 2). Zyte (specialty in protected targets). Pick this lane for the hardest targets at enterprise scale + audit-ready compliance.
Best AI Web Scrapers — Full Reviews
The picks below are ranked on AI-pipeline value — markdown/JSON output, LLM-stack integration, anti-bot success, predictable pricing, and 2026 momentum. Tools win different lanes; pick by your workload, not by overall rank.
1. Firecrawl
Firecrawl is the lane-leader for LLM-ready scraping. It converts any web URL into clean markdown or structured JSON ready for embedding into RAG pipelines, with claimed 67% fewer tokens than raw HTML (relevant: token cost is your downstream LLM bill). Native LangChain + LlamaIndex integration, MCP server for AI coding agents (Claude Code, Cursor), built-in PDF extraction, JavaScript rendering on Hobby+ tiers, and a transparent 1-credit-per-page pricing model starting at $16/mo for 5,000 credits. Failed requests don’t consume credits — a meaningful cost-management property at scale where retries are common. At volume the per-scrape cost compresses to ~$0.0008. The trade-off: anti-bot bypass for tier-1 protected targets (Cloudflare/Akamai/PerimeterX) is on higher tiers or as an add-on; for the hardest targets you may still need to pair with raw proxies.
Quick specs — Output: markdown + structured JSON (native LLM-ready) · Pricing: 1 credit = 1 page; $16/mo for 5K credits; ~$0.0008/scrape at scale · Anti-bot: included on higher tiers / Hobby has basic · Integrations: LangChain, LlamaIndex, MCP (Claude Code/Cursor), Python/Node SDKs · Open-source: API client + some components open-source, hosted product paid.
Best for: RAG pipeline ingestion, LLM agent web access, dataset assembly where markdown output saves token cost.
2. Apify
Apify is the marketplace king with 10,000+ pre-built scrapers (“Actors”) for specific targets — Amazon, LinkedIn, Reddit, TikTok, Instagram, Twitter/X, news sites, e-commerce, real estate, jobs. Each Actor is independently maintained (by Apify + community), with rental fees per Actor on top of compute usage. Compute-based pricing: ~$0.25/CU on the $49 Starter tier, $0.40/CU on pay-as-you-go (drops to $0.16/$0.13 at higher volume tiers) + Actor rental + proxy passthrough (Apify bundles its own residential pool or you can BYO). The marketplace breadth is unmatched — most common targets already have a working scraper, so your engineering time goes to integration, not parser-building. The trade-off: pricing is the hardest to forecast in the AI-scraper space. JS rendering + premium proxy + retry-on-fail compound the compute spend; budgeting requires careful per-Actor estimation. For broad use cases or first-deployment teams, Apify’s marketplace value is hard to beat.
Quick specs — Output: HTML, JSON, CSV depending on Actor · Pricing: compute-based ~$0.25-$0.40/CU (lower at scale: $0.16-$0.13) + per-Actor rental + proxy passthrough · Anti-bot: per-Actor (some bundled, some BYO proxies) · Integrations: Python/Node SDKs, webhooks, scheduled runs, MCP integration in beta · Open-source: Apify SDK is open-source.
Best for: teams that need scrapers across many different sites and prefer not to build each.
3. Octoparse
Octoparse is the visual point-and-click no-code scraper — a desktop application where you click through the target site to define what to extract, with template scrapers maintained for popular targets (Amazon, eBay, Twitter, real-estate sites, etc.) that auto-update when those sites change their layout. $69/mo Standard plan (billed annually; ~$119 on monthly billing) with flat pricing for hundreds of thousands of pages, no per-page metering — predictable for high-volume non-AI-specific workflows. Cloud execution available; built-in anti-bot for the supported template targets. The trade-off: output is HTML/CSV/Excel by default, not LLM-ready markdown — you’ll need a post-processing step to clean for LLM ingestion. If your team is non-technical or you’re a marketing/research org that needs structured data without an engineer, Octoparse is the gentlest learning curve.
Quick specs — Output: CSV, Excel, JSON, HTML (post-process needed for LLM) · Pricing: $69/mo Standard (annual; ~$119/mo monthly); flat pricing, no per-page metering · Anti-bot: built-in for template targets · Integrations: API access on higher tiers · Open-source: closed.
Best for: non-technical teams; visual builders; structured-data extraction for BI/analytics where LLM output isn’t gating.
4. Browse AI
Browse AI is the prompt-driven no-code AI scraper — you describe in plain English what you want to extract, the AI generates the scraper, and it auto-adapts when target sites change. $19/mo entry tier — among the cheapest AI scrapers. The auto-adapt mechanism is the differentiator: when a target site’s layout changes, Browse AI’s AI re-identifies the elements without you re-configuring. Output is structured JSON. The trade-off: large-volume scraping is expensive on Browse AI’s credit model; for hundreds of thousands of pages, ScrapingBee/ScraperAPI/Firecrawl’s per-page rates beat it. Best for non-technical teams running curated daily/weekly extractions on a known set of sites.
Quick specs — Output: structured JSON · Pricing: $19/mo entry tier, credit-based · Anti-bot: auto-adapts; built-in · Integrations: API, webhooks, Zapier · Open-source: closed.
Best for: non-technical teams running structured-extraction workflows on known target sites; rapid prototyping.
5. ScrapingBee
ScrapingBee is the developer-friendly managed API — clean documentation, official Python and Node SDKs, JavaScript rendering on all plans, residential and premium-proxy add-ons, per-request pricing starting around $49/mo Freelance plan. Markets itself on ease-of-use and clear docs rather than feature breadth. The trade-off: per-request multipliers (JS rendering 5×, premium proxies 25×, screenshot 50×) make the effective per-page cost much higher than the base; budget on the upper end. Output is HTML/JSON, not native LLM markdown.
Quick specs — Output: HTML + JSON, BeautifulSoup-friendly · Pricing: $49/mo Freelance; per-request with multipliers (JS 5×, premium 25×) · Anti-bot: built-in on higher tiers · Integrations: Python + Node SDKs, simple REST · Open-source: closed.
Best for: developer teams who want a clean managed API for moderate-defense targets.
6. ScraperAPI
ScraperAPI specializes in the hardest e-commerce targets with dedicated Structured Data Endpoints — point at an Amazon ASIN, get back a parsed JSON product object; same for Google SERP, Walmart, eBay. $49/mo Hobby plan with 100,000 credits for simple HTML pages, more for premium endpoints. Bundled anti-bot for the specialty targets, residential pool included. Lane: specialty managed API for e-commerce + SERP. The trade-off: outside the structured-endpoint targets, it’s a per-request scraper similar to ScrapingBee with similar multipliers.
Quick specs — Output: HTML + structured JSON for specialty targets (Amazon, Google SERP, Walmart, eBay) · Pricing: $49/mo Hobby (100K credits); structured endpoints higher cost · Anti-bot: bundled for specialty targets · Integrations: Python SDK + REST · Open-source: closed.
Best for: e-commerce price-tracking, Amazon/Walmart/Google SERP at scale where the structured endpoints save parsing time.
7. ZenRows
ZenRows specializes in anti-bot bypass — getting past Cloudflare, DataDome, PerimeterX (now HUMAN Security), and similar enterprise WAF stacks. Per-request pricing with multipliers, JS rendering on all plans, premium-proxy bundled. Per the Scrapeway December 2024 benchmark, ZenRows achieved 51% success rate with 15.4s response time at $4.62/1K requests on hard targets — solid but mid-pack vs Bright Data’s ~98%. Lane: specialty managed API for hard-defense targets where general scrapers stall. The trade-off: premium pricing; not the cheapest per-page in the developer-API lane.
Quick specs — Output: HTML + JSON · Pricing: per-request with multipliers · Anti-bot: bundled, specialty in Cloudflare/DataDome/PerimeterX · Integrations: Python SDK + REST · Open-source: closed.
Best for: hard-defense targets (Cloudflare/PerimeterX-protected) where general scrapers fail.
8. Crawl4AI
Crawl4AI is open-source and free — the leading AI-native open-source crawler, designed specifically for RAG pipelines and LLM training data assembly. Returns clean markdown + structured JSON, native to LangChain and LlamaIndex, JavaScript rendering via Playwright, schema-based extraction (Pydantic/Zod), screenshot capture, batch crawling. Self-hosted, so the only cost is your infrastructure (Playwright + proxies + compute). For ML teams who need IP-provenance audit trail (post-NYT-v-OpenAI January 2026 ruling, training-data discovery is the new exposure surface) or want full control over the pipeline, Crawl4AI is the right choice. The trade-off: you bring the anti-bot layer (Playwright stealth + residential proxies); free until you account for the proxy bill.
Quick specs — Output: markdown + structured JSON (native LLM-ready) · Pricing: free, self-hosted · Anti-bot: bring-your-own (Playwright stealth + residential proxies) · Integrations: LangChain, LlamaIndex, MCP, custom Python · Open-source: yes (Apache 2.0).
Best for: ML teams that want full control + IP-provenance audit trail + free at scale (proxy cost only).
How Much Do AI Web Scrapers Cost?
Pricing in 2026 falls into four bands:
- Free open-source — Crawl4AI, Scrapy, Playwright. Cost = your infra + proxy bill.
- Budget managed ($16-$49/mo) — Firecrawl Hobby ($16), Browse AI entry ($19), Decodo Scraping API ($19), Octoparse Free trial, ScrapingBee Freelance ($49), ScraperAPI Hobby ($49).
- Mid-tier ($49-$499/mo) — Apify Personal+, Octoparse Standard ($89), Browse AI mid-plans, Oxylabs Web Scraper API ($49+), ZenRows mid-plans.
- Enterprise per-record ($1.30-$1.50/1K + $499+/mo) — Bright Data Web Scraper API, Oxylabs enterprise, Zyte enterprise.
The real cost question for AI scraping isn’t “what’s the cheapest tool” but “what’s the lowest cost per usable LLM-ready record on my target sites at my volume.” Test 5-10 tools against your actual targets and your downstream LLM pipeline; the per-page cost difference between an LLM-ready markdown scraper (Firecrawl) and a raw-HTML scraper (Octoparse, Apify generic) shows up downstream in token cost, not just the scraper bill.
Is AI Web Scraping Legal?
The 2025-2026 jurisprudence dramatically clarified AI web scraping law — and dramatically shifted the exposure surface. The basics:
- Training on public web data is fair use (US). Bartz v Anthropic (Jun 23, 2025, Judge Alsup) ruled training on public web data “exceedingly transformative” and fair use under 17 USC §107 — but with a carve-out that downloading ~7M pirated books for Anthropic’s library was NOT fair use. Kadrey v Meta (Jun 25, 2025, Judge Chhabria) ruled for Meta on the record but explicitly cautioned it does not stand as broad AI-training-is-fair authority.
- Public scraping is CFAA-safe. hiQ v LinkedIn (9th Cir. April 2022) + Meta v Bright Data (Jan 23, 2024) — public, logged-out web data scraping does not violate the Computer Fraud and Abuse Act.
- Publisher contracts are the new exposure layer. Reddit sued Anthropic (Jun 2025) and Perplexity + Oxylabs (Oct 2025) for unlicensed scraping. Stack Overflow + Cloudflare launched pay-per-crawl (Feb 2026). The RSL protocol (Sep 2025, 1,500+ publishers) gives sites machine-readable licensing terms. Violating publisher ToS triggers contract-breach + state-tort exposure even when CFAA is safe. This is exactly the pattern that hit hiQ (CFAA-safe under the 9th Circuit’s 2022 ruling, but a 2022 settlement on contract-law and California state-tort grounds).
- Personal data triggers parallel privacy law. GDPR (EU), CCPA/CPRA (California), LGPD (Brazil), DPDP (India, phased through May 2027), KVKK (Türkiye) all apply to AI training corpora containing personal data of residents in those jurisdictions. Strip personal data; document the strip step.
- Production discovery is real. NYT v OpenAI (Jan 2026 SDNY ruling): OpenAI was compelled to produce all 20M ChatGPT logs to plaintiffs. Production AI pipelines should now assume eventual discovery — keep scraping logs, robots.txt-respect records, proxy-vendor IP-provenance attestations, and license documentation.
The honest reading: training on public web data is legally defensible in 2026 under Bartz/Kadrey + hiQ + Meta v Bright Data. Publisher-contract exposure (Reddit/SO/RSL signatories) is the real risk surface. Personal-data scraping is the highest risk. Get US + EU + relevant-jurisdiction privacy + tech-transactions counsel before scaling. This isn’t legal advice.
How to Pick an AI Web Scraper
Three-step decision framework:
- Output structure. RAG pipeline / agent context → Firecrawl, Crawl4AI, Olostep, Spider.cloud (LLM-ready markdown native). Generic data extraction → Apify, Octoparse, Browse AI, ScrapingBee (post-process). Specialty targets (Amazon/Google/LinkedIn/Reddit) → Bright Data Web Scraper, ScraperAPI structured endpoints.
2. Anti-bot need. Public + low-defense targets (Wikipedia, Common Crawl, GitHub, arXiv, public APIs) → datacenter proxies + Crawl4AI or Apify-cheap-actors works. Medium-defense (most news, forums, e-commerce catalogs) → ScrapingBee/ScraperAPI/Firecrawl/Apify residential. Hard targets (Cloudflare/Akamai/PerimeterX/HUMAN-protected) → ZenRows specialty, Bright Data Web Scraper, or Crawl4AI + premium residential.
3. Volume + budget. <10K pages/month → cheap managed (Browse AI, Firecrawl Hobby, Decodo Scraping API). 10K-1M pages/month → mid-tier managed (Firecrawl Growth, ScrapingBee, ScraperAPI, Apify, Octoparse). 1M+ pages/month → enterprise managed (Bright Data per-record, Oxylabs) OR self-hosted Crawl4AI + DataImpulse residential at $1/GB. For most production AI/ML teams in 2026, the answer is a stack: Firecrawl for RAG/LLM ingestion of high-quality sources + Apify for broad marketplace coverage + Crawl4AI + DataImpulse residential underneath for self-built pipelines that need IP-provenance audit and volume cost control + Bright Data Web Scraper for the handful of hardest enterprise targets. Don’t pick a single tool; pick a layered stack.
For more on the proxy infrastructure underneath, see our residential proxies product page, the datacenter proxies product page (for public-data layers like Common Crawl mirrors), the best proxies for ML & AI training data collection roundup, and the best proxies for web scraping roundup.
FAQ
What’s the best AI web scraper for RAG pipelines in 2026?
Firecrawl is the lane-leader for RAG — purpose-built LLM-ready markdown output, claims ~67% fewer tokens than raw HTML (saves on downstream token cost), native LangChain + LlamaIndex integrations, MCP server support for AI coding agents. $16/mo entry, $0.0008/scrape at scale. Crawl4AI is the open-source alternative for teams wanting full control + IP-provenance audit trail.
Apify vs Firecrawl — which one?
Apify wins on marketplace breadth (10K+ Actors covering most common targets) and is the right pick when you need scrapers for many different sites. Firecrawl wins on LLM-pipeline alignment, predictable per-page pricing, and ease of use for RAG/agent ingestion. For most modern AI workflows, Firecrawl beats Apify on ROI; for legacy data-extraction across many sites, Apify wins. Many teams use both.
Is Crawl4AI really good enough vs paid scrapers?
Yes, with caveats. Crawl4AI is open-source, AI-native, LangChain/LlamaIndex integrated, returns markdown + JSON ready for LLMs — and free. The trade-off is anti-bot: Crawl4AI runs through Playwright stealth + whatever proxies you bring, so for hard-defense targets (Cloudflare/Akamai/PerimeterX) you need to pair with residential or premium proxies. For ML teams who already run proxies (DataImpulse residential at $1/GB) and want IP-provenance audit trail, Crawl4AI is the right pick.
Which AI scraper has the best anti-bot bypass?
Per Scrapeway 2024-2025 benchmarks: Bright Data Web Scraper API at ~98% average success rate, hitting 100% on Indeed, Zillow, Capterra, Google. ZenRows specializes in Cloudflare/DataDome/PerimeterX/HUMAN bypass at mid-pack success rates. For most teams who don’t need 98%, ScrapingBee + premium residential or Firecrawl on higher tiers handles tier-1 targets.
Is AI web scraping legal?
Training on public web data is fair use under Bartz v Anthropic (Jun 2025) + Kadrey v Meta (Jun 2025); public scraping is CFAA-safe under hiQ + Meta v Bright Data. But publisher contracts (Reddit ToS, Stack Overflow pay-per-crawl, RSL signatories) are enforceable — Reddit sued Anthropic + Perplexity for unlicensed scraping. Personal data triggers GDPR/CCPA/LGPD/DPDP/KVKK. Get counsel before scaling. This isn’t legal advice.
What’s the cheapest AI web scraper?
Crawl4AI (free, self-hosted) is the cheapest if you have engineers to run it + proxies underneath. Among managed APIs: Firecrawl ($16/mo, 5K credits), Decodo Web Scraping API ($19/mo), Browse AI entry ($19/mo) are the cheapest budget tier. For volume cost control above 1M pages/month, self-hosted Crawl4AI + DataImpulse residential at $1/GB beats every managed API.
Do I still need proxies if I use a managed AI scraper?
For fully-bundled managed APIs (Bright Data Web Scraper, Oxylabs Web Scraper, Zyte, ZenRows, ScraperAPI), proxies are included — you don’t separately buy them. For partial-bundle or bring-your-own scrapers (Apify with BYO, Firecrawl on lower tiers, Crawl4AI, Scrapy + Playwright stacks), residential proxies ($1/GB on DataImpulse) are the underlying layer. The trade-off: managed APIs cost $1.30-$1.50/1K records all-in; self-built with raw proxies costs ~$0.50-$1/1K at volume but requires engineering time.
How do I scrape Reddit + Stack Overflow without burning my access?
For Reddit and Stack Overflow specifically, the legal path in 2026 is: Reddit Data API (licensed) or Stack Overflow Stack Exchange API (rate-limited). Unlicensed scraping triggers contract-breach exposure — Reddit sued Anthropic (Jun 2025) and Perplexity + Oxylabs (Oct 2025). If you must scrape: residential or ISP proxies (DataImpulse residential at $1/GB or Decodo ISP at $0.27/IP) + slow human-like cadence + Playwright stealth. Or use Bright Data’s licensed Reddit dataset (paid, audit-defensible).
Open-source vs managed — when do I switch?
Switch to open-source (Crawl4AI, Scrapy, Playwright) when: (a) you’re running 1M+ pages/month and managed-API costs exceed your engineering time to maintain self-hosted; (b) you need IP-provenance audit trail (post-NYT-v-OpenAI January 2026 discovery ruling, training-data exposure is real); (c) your team needs full control over data shape and pipeline. Stay on managed when: time-to-first-data matters more than per-page cost, your team doesn’t have Playwright/proxy ops capacity, or you need the SLA + compliance posture (ISO 27001 + SOC 2) for procurement.
Ready to run AI web scraping with a proxy layer that works underneath any open-source scraper (Crawl4AI, Scrapy, Playwright) or paired with managed APIs that need BYO? Start with DataImpulse — residential from $1/GB, datacenter from $0.50/GB, mobile from $2/GB, pay-as-you-go with ethically-sourced 90M+ IPs across 195 countries, country targeting included (state/city/ZIP/ASN as paid add-on), traffic that never expires, and 24/7 human support.

 State/City/Zip/ASN Targeting
State/City/Zip/ASN Targeting 



